Spring AOP supports the following AspectJ pointcut designators (PCD) for use in pointcut expressions:
execution: For matching method execution join points. This is the primary pointcut designator to use when working with Spring AOP.
within: Limits matching to join points within certain types (the execution of a method declared within a matching type when using Spring AOP).
this: Limits matching to join points (the execution of methods when using Spring AOP) where the bean reference (Spring AOP proxy) is an instance of the given type.
target: Limits matching to join points (the execution of methods when using Spring AOP) where the target object (application object being proxied) is an instance of the given type.
args: Limits matching to join points (the execution of methods when using Spring AOP) where the arguments are instances of the given types.
@target: Limits matching to join points (the execution of methods when using Spring AOP) where the class of the executing object has an annotation of the given type.
@args: Limits matching to join points (the execution of methods when using Spring AOP) where the runtime type of the actual arguments passed have annotations of the given types.
@within: Limits matching to join points within types that have the given annotation (the execution of methods declared in types with the given annotation when using Spring AOP).
@annotation: Limits matching to join points where the subject of the join point (the method being run in Spring AOP) has the given annotation.
// Compile parses a regular expression and returns, if successful, a Regexp // object that can be used to match against text. funcCompile(str string) (regexp *Regexp, err error) {
graph LR 0--A-->66 0--C-->68 0--Z-->91 66--C-->69 66--D-->70
69的字节点为74和75, 权重为74-5=69和75-5=70, 分别是E和F
1 2 3 4 5 6 7 8
graph LR 0--A-->66 0--C-->68 0--Z-->91 66--C-->69 66--D-->70 69--E-->74 69--F-->75
当然,后面的笔者就不进行模拟了,到此为止。
4. 双数组字典树的构建算法
首先算法的第一步是构建一颗字典树,你需要将这颗字典树构建出来。字典树的代码如下,这个不用多说了
1 2 3 4 5 6 7 8 9
voidaddTire(constchar* str, int len) { int root = 1; for (int i = 0; i < len; i++) { if (tire[root][str[i]] == 0) { tire[root][str[i]] = ++tireTot; } root = tire[root][str[i]]; } }
第二步,就是在字典树上进行BFS,在BFS过程中增量构建双数组字典树,当我们BFS到某个节点U的时候,便开始寻找,当前还有哪个base值没有被使用,可以使得这个U的子节点的check值均为0, no BB , show code
先找到U的所有子节点
1 2 3 4 5 6 7 8
vector<int> sonTransList; for (int i = 0;i < maxCharest;i++) { if (tire[tireTop][i] != 0) { sonTransList.push_back(i); tireQ.push(tire[tireTop][i]); } } cout << "find son: " << sonTransList.size() << endl;;
然后寻找一个合适的base值,这个值储存在变量begin中
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// find begin while (true) { begin++; bool ok = true; for (int son : sonTransList) { if (check[begin + code[son]] != 0) { ok = false; break; } } if (ok) { break; } }
while (!tireQ.empty()) { int tireTop = tireQ.front(); tireQ.pop();
vector<int> sonTransList; for (int i = 0;i < maxCharest;i++) { if (tire[tireTop][i] != 0) { sonTransList.push_back(i); tireQ.push(tire[tireTop][i]); } } cout << "find son: " << sonTransList.size() << endl;;
// find begin while (true) { begin++; bool ok = true; for (int son : sonTransList) { if (check[begin + code[son]] != 0) { ok = false; break; } } if (ok) { break; } }
base[tireState2DatState[tireTop]] = begin; for (int i = 0;i < maxCharest;i++) { if (tire[tireTop][i] != 0) { int son = i; if (check[begin + code[son]] != 0) { exit(-1); } check[begin + code[son]] = begin; tireState2DatState[tire[tireTop][i]] = begin + code[son]; } } for (int i = 0;i < 1000;i++) { if (check[i] != 0 || base[i] != 0) { cout << i << " " << base[i] << " " << check[i] << endl; } } cout <<begin<<"--------" << endl; }
}
intmain() {
for (int i = 0;i < 7;i++) { addTire(stringData[i].data(), stringData[i].size()); } buildDAT();
GOROOT=/usr/local/Cellar/go/1.17.2/libexec #gosetup GOPATH=/Users/s/go #gosetup /usr/local/Cellar/go/1.17.2/libexec/bin/go build -o /private/var/folders/6t/kt2nf9z17cv87lqk842lngj80000gn/T/GoLand/___go_build_gin_demo gin-demo #gosetup /private/var/folders/6t/kt2nf9z17cv87lqk842lngj80000gn/T/GoLand/___go_build_gin_demo [GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production. - using env: export GIN_MODE=release - using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] GET / --> main.main.func1 (3 handlers) [GIN-debug] Environment variable PORT is undefined. Using port :8080 by default [GIN-debug] Listening and serving HTTP on :8080 [GIN] 2021/10/19 - 15:02:00 | 200 | 16.428µs | ::1 | GET "/"
sh-4.2$ jmap -finalizerinfo 370 Attaching to process ID 370, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.252-b4 Number of objects pending for finalization: 0
"Finalizer" #3 daemon prio=8 os_prio=0 tid=0x00007fd8506eb000 nid=0x1a7 in Object.wait() [0x00007fd77b826000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:144) - locked <0x000000008023bb50> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:165) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:216)
"Reference Handler" #2 daemon prio=10 os_prio=0 tid=0x00007fd8506de800 nid=0x1a6 in Object.wait() [0x00007fd77baf9000] java.lang.Thread.State: WAITING (on object monitor) at java.lang.Object.wait(Native Method) at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) - locked <0x00000000802478a8> (a java.lang.ref.Reference$Lock) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153)
sh-4.2$ jinfo 370 Attaching to process ID 370, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.252-b4 Java System Properties:
sh-4.2$ jhat dump.bin Reading from dump.bin... Dump file created Fri Sep 24 19:38:36 CST 2021 Snapshot read, resolving... Resolving 4748880 objects... Chasing references, expect 949 dots............. Eliminating duplicate references.............. Snapshot resolved. Started HTTP server on port 7000 Server is ready.
Javah
用于编写JNI方法
JavaP
字节码分析工具
Jshell
Java交互式工具
1 2 3 4 5 6 7 8 9 10 11 12 13
sh-4.2$ jshell | 欢迎使用 JShell -- 版本 16.0.2 | 要大致了解该版本, 请键入: /help intro jshell> int a = 1 a ==> 1 jshell> int b = 1 b ==> 1 jshell> System.out.print(a+b) 2 jshell>



 AspectJ安装
AspectJ安装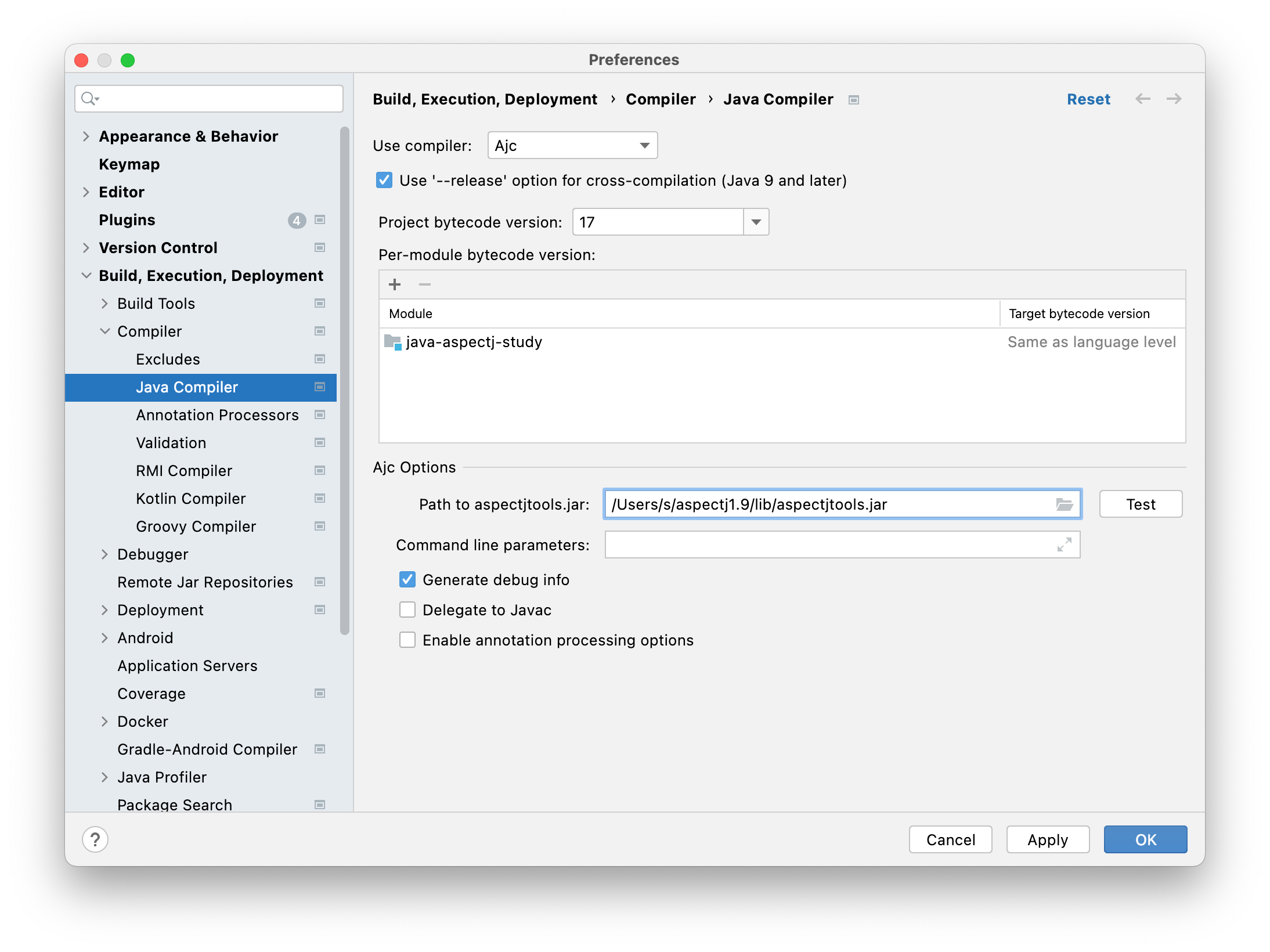 IDEA_Enable_AJC
IDEA_Enable_AJC Add_AJC_Lib.png
Add_AJC_Lib.png