
Springfox使用
1. 对List不能很好的支持
1.1. 核心代码
代码中写的是数组
1 | /** |
1.2. 问题详情
在swagger页面展示的例子是字符串
1 | { |
1.3. 问题讨论
1.4. 解决方案
Go入门-常见陷阱
1. Go 的指针
Go的指针和C的指针很类似,这也是Go被归类于C类语言的原因,Go的指针不支持偏移运算,即不能向C一样让指针+1,-1。
1.1. 正常使用
先来看第一个,符号&即可取到对象的地址。
1 | func sample1() { |
1 | [0 1 2 3 4 5 6 7 8 9] |
1.2. for循环问题
下面的输出全是9,因为for循环的value是共用一个地址的。
1 | func sample2() { |
2. Go 的 new 和 make
new 只分配内存,make不仅分配内存还初始化对象。
slice、chan、map一般可以使用make初始化。
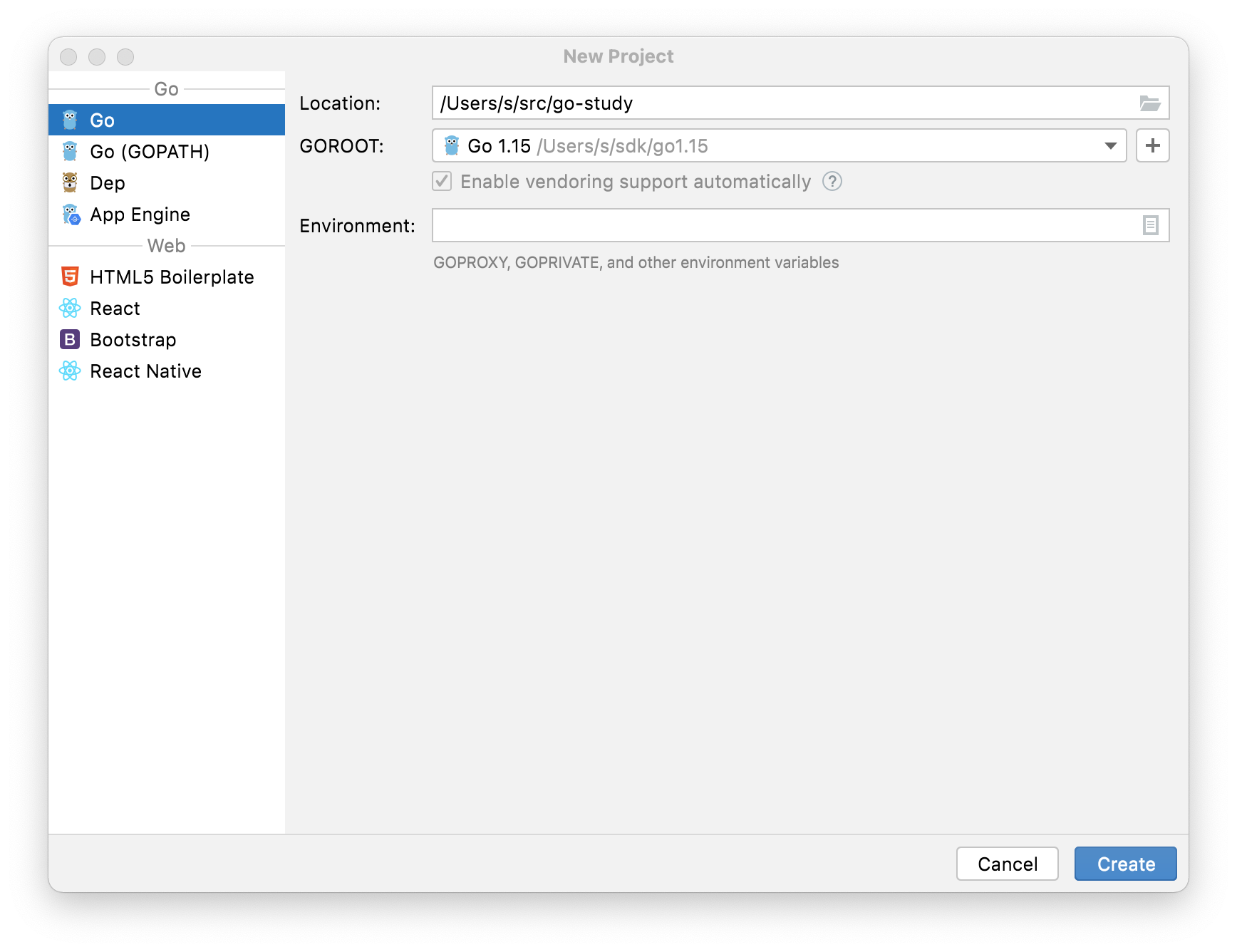
Go进阶-Module
1. Module使用
在文章Go入门-Go语言从入门到进阶实战中,我们介绍了GO项目的结构,但是没有解释其中的一个文件go.mod, 这其实是模块的意思。在go.mod中可以引入go的依赖。
1 | require ( |
这里简单介绍一下,注意到这里是库名加版本号。当我们引入了依赖管理以后,就可以在自己的项目中直接import三方包了。
2. Module 的历史
Go modules 是 Go 语言的依赖解决方案,发布于 Go1.11,Go1.14 上已经明确建议生产上使用了
一开始go发布的时候是没有包管理的
go get命令会根据路径,把相应的模块获取并保存在
$GOPATH/src也没有版本的概念,
master就代表稳定的版本原文: 😊
在Go Module出现以前,我们使用Go Get获取库,库会直接下载到GOPATH目录的src文件夹下,很好用但是有一个问题-版本兼容问题。
当两个库依赖分别同一个库的v1和v2版本的时候,如果v1和v2不兼容,那么会导致这两个库无法同时使用。
后来官方采用了vgo方案来解决GO的依赖管理问题,也就是现在的Go modules。
Go入门-Effective-Go
1. Effective GO
https://github.com/bingohuang/effective-go-zh-en
2. 格式化
在最开始学习GO的时候,写了几篇Blog,发现代码里面的对齐都是TAB,这让我很困惑,知道现在才知道,GO语言,默认使用TAB进行对齐。
当然GO还有自己的空格规则x<<8 + y<<16,向这份代码,我们根据空格就能知道计算的优先级了。
3. 注释
3.1. 包注释
Go语言要求package语句前加上注释,来介绍整个包,如果package包含多个文件,则只需要在其中一个文件中标注即可。
1 | /* |
Go进阶-Web框架
0. 前言
简单介绍Beego和Gin,水一水文章。
1.1. 安装Beego库
1 | go get github.com/astaxie/beego |
同时安装Bee工具
1 | go get github.com/beego/bee |
看到如下内容代表安装成功
1 | s@HELLOWANG-MB1 ~ % go get github.com/astaxie/beego |
双数组字典树
0. 前置知识
1. 双数组字典树介绍
双数组字典树英文名为DoubleArrayTrie,他的特点就是使用两个数组来表示一颗字典树,这里有比较有趣了,两个数组是怎么表达出字典树的呢?
2. 双数组介绍
顾名思义,有两个数组,一个是base,另一个是check。
首先介绍数组的下标,数组的下标代表字典树上节点的编号,一个下标对应一个节点。
其实base数组的作用是用来记录一个基础值,这个值可以是随机值,只要不产生冲突就可以了,所以这个值可以用随机数算法获取,当然这样效率不高,高效的做法应该是使用指针枚举技术,ok,现在你已经明白了,base数组是一个不产生冲突的随机数组。
最后,check数组,check数组与base数组相互照应,如果base[i]=check[j] 则说明j是i的儿子,而且i到j的边权恰好为j-base[i],也可以写作j-check[j]好好理解这句话
从另一个方面而言,双数组字典树的base数组,应该是一个指针数组,他指向了一个长度为字符集大小的数组的首地址,而check数组是一种hash碰撞思路,由于base数组疯狂指向自己,导致产生了很多碰撞,但是由于字典树是一个稀疏图,导致儿子节点指针利用率低,所以base数组疯狂复用这段空间,最后必须要依赖check来解决冲突,
双数组字典树相比于传统字典树,仅仅只在内存方面于增删改查占有优势,但是唯一不好的地方就是删和改会导致base数组内存分裂,难以回收,删和改如果占大头,那么传统字典树的内存效率更高
由于搜索领域几乎不涉及到删和改,所以这个数据结构很nice,字符集多大,就节省了多少倍的空间
数据结构很棒,但是在现在这个内存不值钱的时代,这些指针的储存用hashmap直接无脑顶掉,空间占用也高不了多少,hashmap顶多浪费两倍空间
两倍的空间算不上啥,除非这是唯一的优化点,否则不会优化到这个数据结构上来

Go进阶-协程的本质与CPU的争夺
1. 从协程谈起
很多语言都支持协程,那什么是协程,和线程进程有什么区别呢?这里推荐一篇Blog,笔者直接提取其中最重要的部分
进程、线程 和 协程 之间概念的区别
对于 进程、线程,都是有内核进行调度,有 CPU 时间片的概念,进行 抢占式调度(有多种调度算法)
对于 协程(用户级线程),这是对内核透明的,也就是系统并不知道有协程的存在,是完全由用户自己的程序进行调度的,因为是由用户程序自己控制,那么就很难像抢占式调度那样做到强制的 CPU 控制权切换到其他进程/线程,通常只能进行 协作式调度,需要协程自己主动把控制权转让出去之后,其他协程才能被执行到。
goroutine 和协程区别
本质上,goroutine 就是协程。 不同的是,Golang 在 runtime、系统调用等多方面对 goroutine 调度进行了封装和处理,当遇到长时间执行或者进行系统调用时,会主动把当前 goroutine 的CPU (P) 转让出去,让其他 goroutine 能被调度并执行,也就是 Golang 从语言层面支持了协程。Golang 的一大特色就是从语言层面原生支持协程,在函数或者方法前面加 go关键字就可创建一个协程。
操作系统是不知道协程的,那么应用层如何实现协程呢?下面给一些伪代码
1 | 不断循环: |
我们可以看到,其实这里正在执行的任务就是协程,这样的线程模型,他的CPU利用率非常高,他的协程切换代价非常低,几乎只需要入队出队而已。
但是这样的模型有一个很大的缺点,那就是CPU的公平性,如果一个协程迟迟不退出,且不进行系统调用,也不主动释放CPU,那么,这个协程将造成队头阻塞现象。