

Hadoop
安装
Docker Install
1 | echo -e "===prepare workspace===" |
1 | FROM centos:centos8 |
K8S Install
1 | cd . |
Hadoop概述
优点
- 高可靠
- 高拓展
- 高效性
- 高容错
HDFS
HDFS是分布式文件系统,包含NameNode, DataNode和Secondary NameNode
| 组件 | 功能 |
|---|---|
| NameNode | 储存文件的元数据 |
| DataNode | 储存文件块,校验和 |
| Secondary NameNode | 协助NameNode处理元数据 |
YARN
YARN是分布式资源调度器,包含了ResourceManager, NodeManager, ApplicationMaster, Container
| 组件 | 功能 |
|---|---|
| ResourceManager | 处理客户端请求,监控NodeManager, 启动ApplicationMaster, 分配和调度资源 |
| NodeManager | 管理单个节点上的资源,处理ResourceManager和ApplicationMaster的命令 |
| ApplicationMaster | 切分数据,为应用程序申请资源,并分配给任务,处理任务的监控和容错 |
| Container | 代表节点的CPU,内存,磁盘,网络 |
MapReduce
MapReduce是一个计算模型, Map阶段并行处理数据,Reduce阶段对Map汇总
HDFS
HDFS全称为Hadoop Distributed File System,适用于一次写入,多次读出,不支持修改
Block
文件分块存储,默认是128M,block的寻址时间一般为10ms,寻址时间为传输时间的1%的时候,达到最佳状态,机械硬盘的速率是100M/s, 所以文件分块的大小为100M 较佳,近似到128M.
$$
10ms / 1% \to 1s\
1s / 100MB/s \to 100MB \
100MB \to 128MB
$$
block太小增加寻址时间,太大会导致数据传输的时间过长,所以block的大小取决于磁盘的传输速率
HDFS shell
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
HDFS读写文件
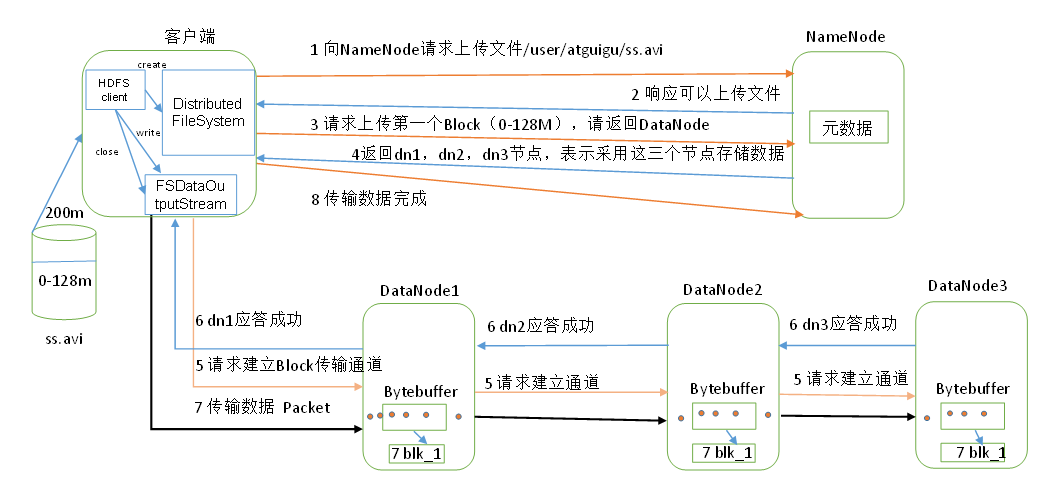
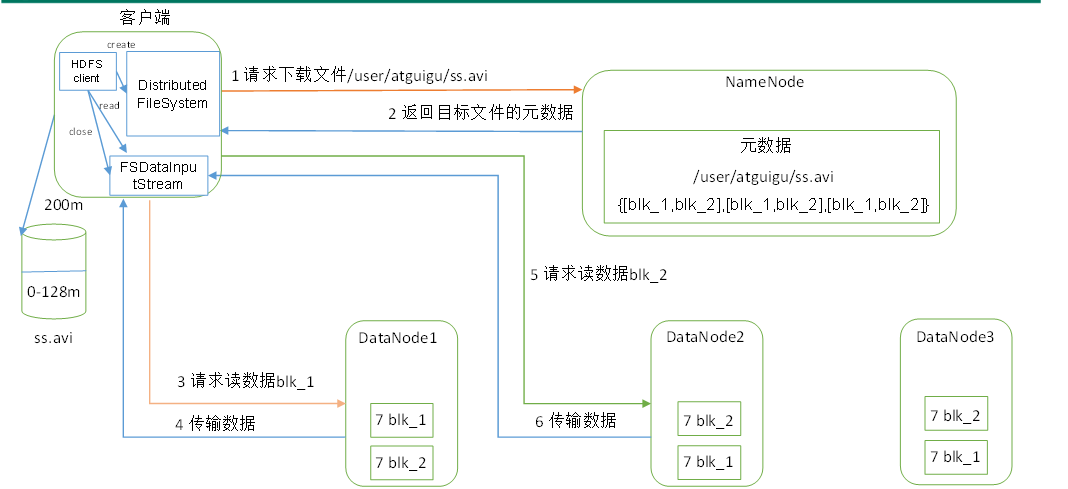
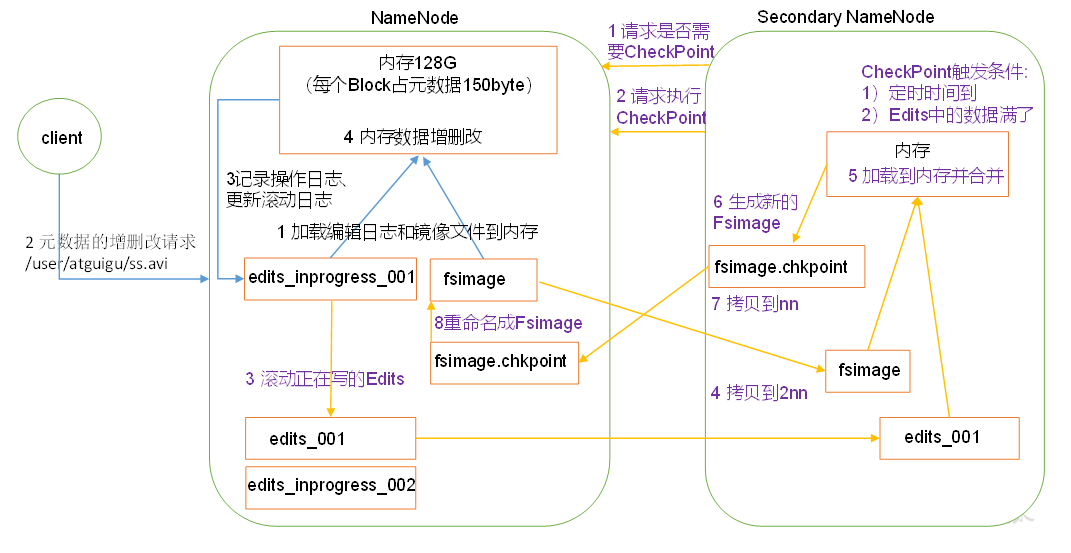
NameNode工作机制
NameNode将内存数据持久化到磁盘中,分为fsimage和edits两个文件,fsimage是老的内存镜像,edits是追加格式的日志,表示着内存的变化情况,随着NameNode工作,edits会越来越大,这时候SecondaryNameNode会协助NameNode将edits与fsimage合并为新的fsimage。 注意下图紫色部分的流程即可
集群安全模式
当NameNode不是第一次启动的时候,会加载Fsimage,并执行Edits日志,最后合并,此后开始监听DataNode请求,这个过程中NameNode一直是安全模式,文件系统处于只读状态,如果满足最小副本数,NameNode会在30秒后退出安全模式
NameNode多目录配置
1 | <property> |
当我们配置了多个目录以后, NameNode的数据会同时存储在这些目录中,这些目录中的内容是一样的,如果一个目录损坏,NameNode会通过另一个目录恢复
DataNode工作机制
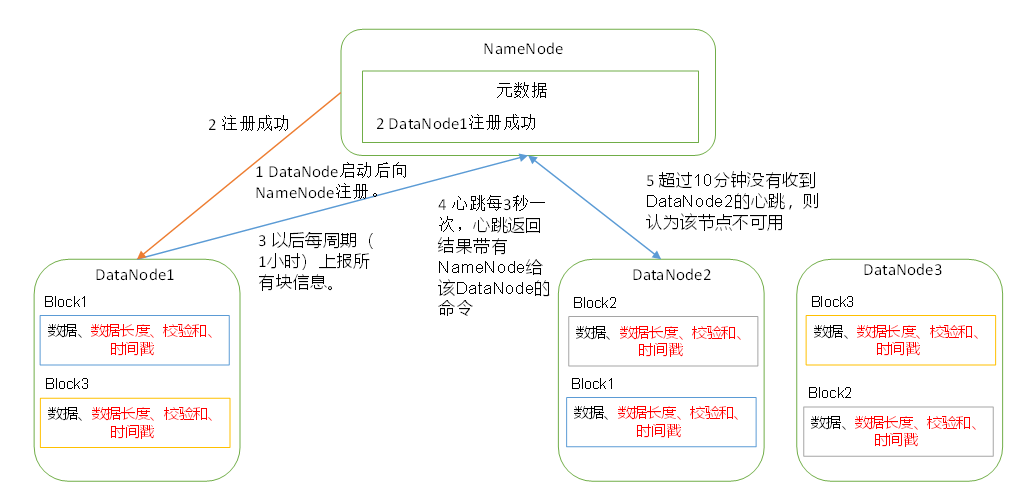
超时时间是2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.hertbeat.interval
MapReduce
全过程
(input) <k1, v1> -> map -> <k2, v2> -> combine -> <k2, v2> -> reduce -> <k3, v3> (output)
InputFormat
InputFormat是执行MapReduce的第一步,他主要用于在从HDFS文件系统输入到MapTask的过程
| 名词 | 解释 |
|---|---|
| 数据块 | Block是HDFS物理上把数据分成的多块 |
| 数据切片 | Split是逻辑上对数据的分片,每个Split由一个MapTask处理 |
| 切片方法 | 备注 |
|---|---|
| TextInputFormat | 按照大小切片,kv分别是行偏移量和行的具体数据 |
| KeyValueTextInputFormat | 按照大小切片,kv是每一行由分隔符分割的左右两部分 |
| NLineInputFormat | 按照行数切片,kv分别是行偏移量和行的具体数据 |
| CombineTextInputFormat | 按照大小拆分大文件,合并小文件,kv分别是行偏移量和行的具体数据 |
Map
当经过了InputFormat以后,数据就进入到了Map阶段,
在这个阶段,Map框架会对每一对KV进行并行处理,并输出为新的KV,
把新的KV写入环形缓冲区,一端写索引,另一端写数据,
直到环形缓冲区达到80%(80MB),Map框架将缓冲区数据排序并写入磁盘文件进行分区
直到文件数量达到一定上限,Map框架将文件排序合并,并进行分区
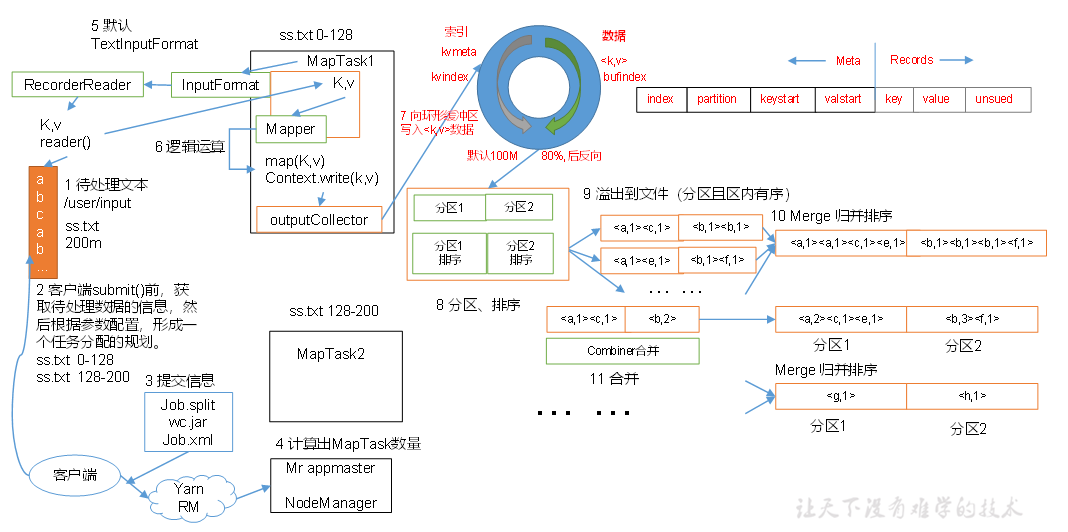
Partition
Map后,需要将数据写入不同的分区,
ReduceTask数大于分区数,则最后几个Reduce为空
ReduceTask小于分区数大于1,则异常
ReduceTask=1,则只有一个输出文件
默认的分区是HashPartitioner
MapReduce中的排序
MapReduce两个阶段都会进行排序,不管实际是否需要
- Map: 环形缓冲区 -> 达到80% -> 快排 -> 写入文件 -> Map完成 -> 所有文件归并排序
- Reduce: 远程拷贝文件到内存-> 达到内存阈值-> 写入一个磁盘文件-> 磁盘文件个数达到阈值-> 合并文件 -> 拷贝完成-> 所有数据(磁盘+内存)归并排序
排序的方法
- 部分排序: 输出是多个文件,保证每个文件有序
- 全排序: 输出是一个文件,保证这个文件有序
- 辅助排序:
- 二次排序: 排序中有两个判断条件
如何排序
实现WriteableCompable接口即可
Combiner
Combiner就是一个局部的Reduce,他不一定必要,并不通用于所有的MR程序,比如求平均值,但是在局部Reduce不影响全局Reduce的情况下它可以降低网络传输压力
1 | job.setCombinerClass(IntSumReducer.class); |
Shuffle
往往我们称Map之后,Reduce之前的操作为Shuffle
Reduce
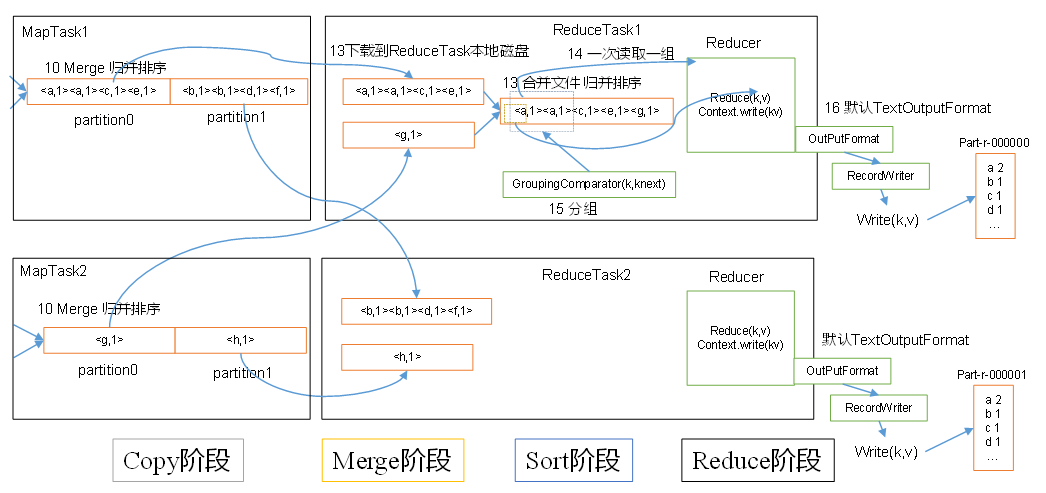
OutputFormat
| OUTPUTFORMAT | 描述 |
|---|---|
| TextOutputFormat | 把结果写成文本行 |
| SequenceFileOutputFormat | 写成二进制文件 |
Join
在Reduce端Join: 用同一个key即可
在Map端Join: 用字典手动Join
Compress
支持gzip,bzip,Lzo等压缩方式,可以用于输入文件的解压缩,输出文件的压缩,mapreduce中间文件的压缩
Map端压缩
1 | configuration.setBoolean("mapreduce.map.output.compress",true); |
Reduce压缩
1 | FileOutputFormat.setCompressOutput(job,true); |
MR速度慢的原因
计算机性能: CPU、内存、磁盘、网络
IO: 数据倾斜,小文件多,不可分块的超大文件多,spill次数多,merge次数多
MR优化
- 输入阶段:合并小文件
- Maper阶段:调整环形缓冲区大小和溢写比例
- Maper阶段:调整合并文件的文件个数阈值
- Maper阶段:使用Combiner
- Reduce阶段:合理设置Map Reduce个数
- Reduce阶段:调整slowstart.completedmaps,提前申请Reduce资源
- Reduce阶段:MapTask机器文件 -> ReduceTask机器Buffer -> 磁盘 -> Reduce, 调整Buffer,让Buffer中保留一定的数据,直接传给Reduce
- 压缩数据
- 开启JVM重用
Yarn
流程
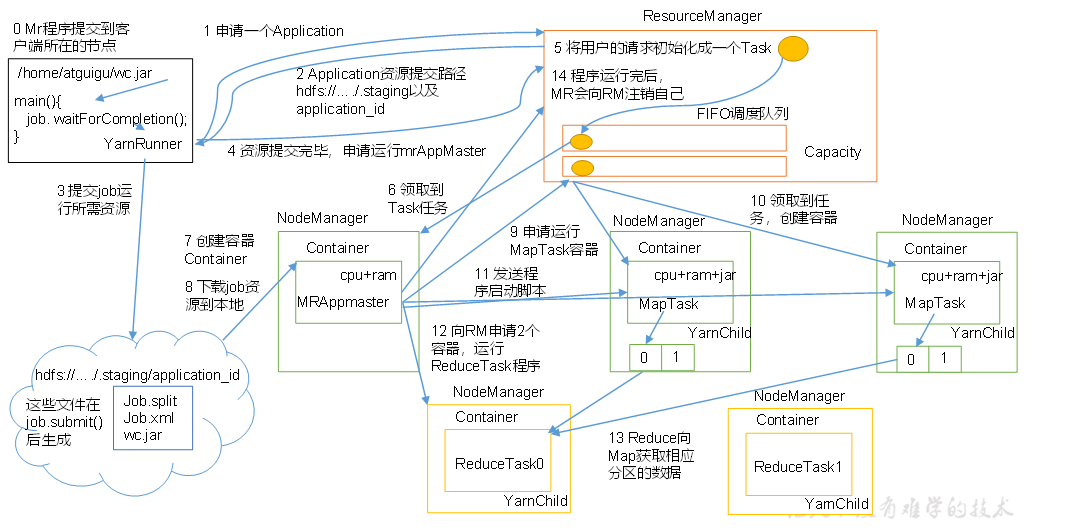
调度器
- FIFIO调度器: 先进先出
- 容量调度器(默认):支持多个队列,每个队列 有一定的资源,各自采用FIFO,对同一个用户的作业所占资源进行限制,安装任务和资源比例分配新的任务,按照任务优先级、提交时间、用户的资源限制、内存限制对队列中的任务排序
- 公平调度器(并发度非常高): 多个队列,每个队列中的job可以并发运行,可以每个job都有资源,哪个job还缺的资源最多,就给哪个job分配资源
任务推测执行
当前Job已完成的Task达到5%, 且某任务执行较慢,则开始备份任务
$$
当前任务完成时刻 = 当前时刻 +(当前时刻 - 任务开始时刻)/ 任务运行进度\
备份任务完成时刻 = 当前时刻 + 所有任务平均花费时间
$$
每个任务最多一个备份任务,每个作业也有备份任务上限
HA
HDFS HA
YARN HA


- 本文作者: fightinggg
- 本文链接: http://fightinggg.github.io/yilia/yilia/QFH340.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!