

版本
使用6.2.4
sds.h sds.c
内存对齐
__attribute__((__packed__))可以让编译器对结构体不进行内存对齐,详细参考
1 |
|
宏##
##后标识的字符串会被替换,然后其左右的内容加上自己会被合并到一起,编译器将其视为标识符进行解析,详细参考
sds.h 源码
sds 可以被简单的认为是一个 char*
1 | typedef char *sds; |
接下来是5种 sds 他们是sdshdr5, sdshdr8, sdshdr16, sdshdr32, sdshdr64, 分别可以储存长度为$2^5$, $2^8$, $2^{16}$, $2^{32}$, $2^{64}$ 的字符串。
__attribute__ ((__packed__))是编译器指令,可以取消内存对齐,让内存紧凑排列,这部分首先看后四个结构体,他们的内存结构定义几乎一摸一样。
len: 字符串的长度
alloc: 分配的空间大小
flags: 字符串的类型(5种),所以只有最低的三位有意义,高5位不做使用。
buf: 字符串的实际内容
对于sdshdr5,他比较特殊,实际上他的len和alloc一定相等,并储存于flags的高5位上,借此实现了内存压缩。
1 | /* Note: sdshdr5 is never used, we just access the flags byte directly. |
sds 把字符串的内容,以及他的元信息(字符串类型、字符串长度、字符串分配的空间)储存在了一起,让内存排列更加紧致。
adlist.c adlist.h
很普通的链表,并没有什么很特殊的地方,注意listIter的direction是迭代器的方向。
1 | typedef struct listNode { |
mt19937-64.c mt19937-64.h
梅森素数
在OEIS上,梅森素数有这些, 维基百科上也有说明, 我们需要注意到的是$2^{19937}-1$是一个梅森素数
线性反馈移位寄存器
线性反馈移位寄存器(Linear Feedback Shifting Register,简称 LFSR)
假设你有一个寄存器,寄存器中储存着一些二进制位,寄存器中有几个位被标记了,接下来会有无限轮操作,每轮操作如下
- 寄存器输出最低位x(x=0或1)。
- 寄存器选择被标记的位和x,取出其值,放到一起进行异或,得到y(y=0或1)。
- 寄存器把自己右移1位,然后把值y放入最高位。
具体来说,你有一个$8$位寄存器,初始储存着$00001111$,其中$3$,$5$,$7$位被标记了,于是开始操作。
第一轮输出$x=1$,然后从低位到高位选择了$1$,$0$,$0$, 最后$y=1 \oplus1 \oplus 0 \oplus 0=0$,寄存器变成了$00000111$
第二轮输出$x=1$,然后从低位到高位选择了$1$,$0$,$0$, 最后$y=1 \oplus1 \oplus 0 \oplus 0=0$,寄存器变成了$00000011$
第三轮输出$x=1$,然后从低位到高位选择了$0$,$0$,$0$, 最后$y=1 \oplus 0 \oplus 0 \oplus 0=1$,寄存器变成了$10000001$
第四轮输出$x=1$,然后从低位到高位选择了$0$,$0$,$0$, 最后$y=1 \oplus 0 \oplus 0 \oplus 0=1$,寄存器变成了$11000000$
第五轮输出$x=0$,然后从低位到高位选择了$0$,$0$,$1$, 最后$y=0 \oplus 0 \oplus 0 \oplus 1=1$,寄存器变成了$11100000$
……
梅森旋转算法
这是一个随机数生成算法,这里有一篇有趣的Blog,有兴趣可以读一下。这里引用一些主要内容。
梅森旋转算法(Mersenne Twister Algorithm,简称 MT)
$32$ 位的梅森旋转算法能够产生周期为 $P$ 的 $w$-比特的随机数序列${\vec x_i}$;其中 $w=32$。这也就是说,每一个$\vec x$ 是一个长度为 $32$ 的行向量,并且其中的每一个元素都是二元数域$\mathbb{F}_2 \overset{\text{def}}{=} {0, 1}$中的元素。现在,我们定义如下一些记号,来描述梅森旋转算法是如何进行旋转(线性移位)的。
- $n$:参与梅森旋转的随机数个数;
- $r$:$[0, w)$ 之间的整数;
- $m$:$(0, n]$之间的整数;
- $\mathbf{A}$:$w \times w$ 的常矩阵;
- $\vec x^{(u)}$:$\vec x$的最高 $w - r$ 比特组成的数(低位补零);
- $\vec x^{(l)}$:$\vec x$的最低 r 比特组成的数(高位补零)。
梅森旋转算法,首先需要根据随机数种子初始化$ n $个行向量:
$$
\vec x_0, \vec x_1, \ldots, \vec x_{n - 1}.
$$
而后根据下式,从$ k=0$ 开始依次计算 $\vec x_{n}$:
$$
\begin{equation}\vec x_{k + n} \overset{\text{def}}{=} \vec x_{k + m}\oplus \bigl(\vec x_{k}^{(u)}\mid \vec x_{k + 1}^{(l)}\bigr)\mathbf{A}.\label{eq:twister}\end{equation}
$$其中,$\vec x\mid \vec x’$表示两个二进制数按位或;$\vec x\oplus \vec x’$表示两个二进制数按位半加(不进位,也就是按位异或);$\vec x\mathbf A$ 则表示按位半加的矩阵乘法。在 MT 中,$\mathbf A$ 被定义为
$$
\begin{pmatrix}
& 1 \
& & 1 \
& & & \ddots \
& & & & 1 \
a_{w - 1} & a_{w - 2} & a_{w - 3} & \cdots & a_0
\end{pmatrix}
$$
我们现在看看这个计算和旋转有什么关系。首先不考虑矩阵$\mathbf A$.
则有$\vec x_{k + n} \overset{\text{def}}{=} \vec x_{k + m}\oplus \bigl(\vec x_{k}^{(u)}\mid \vec x_{k + 1}^{(l)}\bigr)$, 这个式子笔者看了很久才明白他就是$w$轮线性反馈移位寄存器变换。下图是计算$x_n$的时候的异或情况, 可以看到$x_n$的每一个位都是独立的异或

回过头来看 2 式,不难发现,这其实相当于一个 $nw - r$ 级的线性反馈移位寄存器(取 $\vec x_k^{(u)}$的最高 $w−r$ 位与 $\vec x_{k + 1}^{(l)}$的最低 $r $位进行迭代异或,再经过一个不影响周期的线性变换 $\mathbf A$)。只不过,2 式每一次运算,相当于 $LFSR$ 进行了 $w$ 轮计算。若 $w$ 与 $nw−r$ 互素,那么这一微小的改变是不会影响 $LFSR$ 的周期的。考虑到 $LFSR$ 的计算过程像是在「旋转」,这即是「梅森『旋转』」名字的来由。
mt19937源码
主要的计算都在这里
1 | unsigned long long genrand64_int64(void) |
然后是63位生成
1 | /* generates a random number on [0, 2^63-1]-interval */ |
实数的生成
1 | /* generates a random number on [0,1]-real-interval */ |
dict.c dict.h
字典源码
字典结构体定义,需要注意这里有两个dictht,即两个字典,这涉及到了一个重hash问题,redis使用了渐进式rehash算法,即把重hash分布到各个地方(插入、查询等),使得重hash的复杂度降低为$O1$,
redis是单线程,绝对不能出现过于耗时的操作,否则影响redis延时
1 | typedef struct dict { |
server.h server.c-1-跳表
跳表定义在这里
1 | /* ZSETs use a specialized version of Skiplists */ |
intset.c intset.h
整数集合,这里可以储存整数
1 | typedef struct intset { |
encoding是编码方式,指的是contents中的数据如何储存,编码方式分为三种
1 | /* Note that these encodings are ordered, so: |
length是数字的个数
contents是内容,但是他不一定是8位的整数,取决于encoding的值。
整数集合升级
由于整数集合初始情况储存的是INTSET_ENC_INT16,当你插入一个32位的数字以后,会出现溢出,这时候就需要进行升级,就直接开辟新的空间然后拷贝过去,复杂的$O(N)$
不支持降级
ziplist.c ziplist.h
压缩列表
server.h server.c-2-对象
redis对象都在这里统一起来
1 | typedef struct redisObject { |
server.h-3-db
这次主要关注redisServer,这个结构体有460行,笔者省去了一些,可以砍刀redisDb是一个数组,dbnum记录他的数量,一般情况下,dbnum为6
1 | struct redisServer { |
然后是客户端这边, 注意到client,. 这里也有一个指针,当然他指向的就是当前使用的db,而不是数组。
1 | typedef struct client { |
看完服务器和客户端,然后看db
1 | /* Redis database representation. There are multiple databases identified |
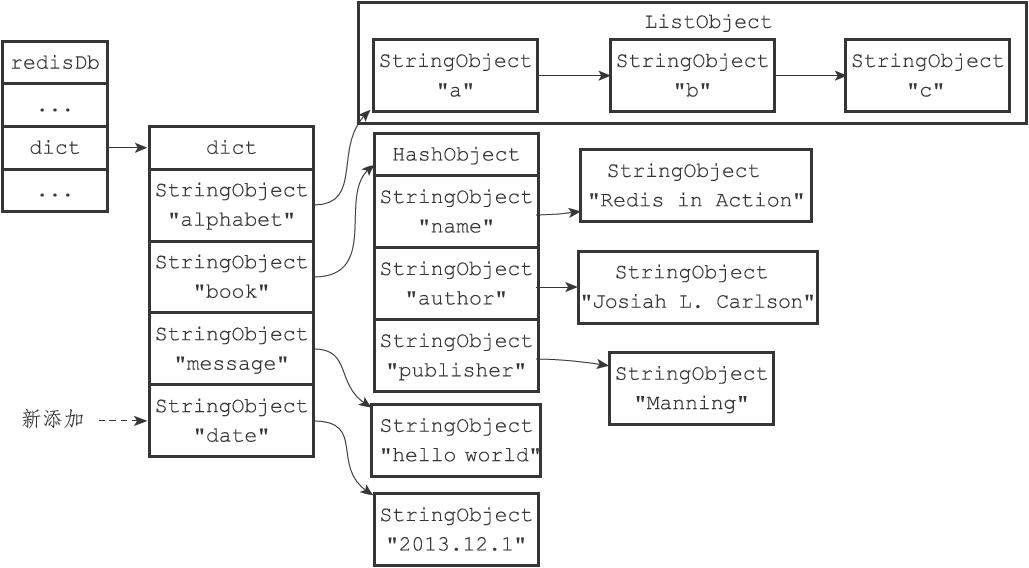
对于redisDb,笔者这里引用一下《Redis设计与实现》中的一个图,读者可以看的更加清晰
rio.c rio.h
rio即redis io, 主要实现了redis中的io操作, rio是一个结构体,他就是_rio, 下面是源码。
1 | struct _rio { |
简单来说,他的这些字段,分别对应这些内容:
| 字段 | 内容 |
|---|---|
| read | 读数据,是函数指针 |
| write | 写数据,是函数指针 |
| tell | tell,是函数指针 |
| flush | flush,是函数指针 |
| update_cksum | 校验和,是函数指针 |
| cksum | 当前校验和 |
| flags | 是否发生读写错误 |
| processed_bytes | 已经处理的字节数 |
| max_processing_chunk | 单次最大处理的字节数 |
| io | 具体的读写目标 |
这里的函数指针主要作用是给后面的下面这些函数使用,这种编程方式有一点像面向对象中的抽象类。注意看,下面的rioWrite使用了对象r的write方法,实现了任意 长度len的写入。而对象r的write方法是不支持任意长度len的。rioRead也是同理了。
1 | static inline size_t rioWrite(rio *r, const void *buf, size_t len) { |
这里有一个有趣的函数
1 | /* Flushes any buffer to target device if applicable. Returns 1 on success |
其中的UNUSED来自于一个宏 #define UNUSED(V) ((void) V), 其作用是消除编译器的警告: 变量未使用。
最后是整个bufferio的源码, 定义了一些函数,这些函数只给rioBufferIO这个对象使用。这是一种单例模式。
1 | /* ------------------------- Buffer I/O implementation ----------------------- */ |
文件io和缓冲区io相差不大,注意关注文件io的写函数,这里涉及到一个异步刷盘的问题。
redis对多个操作系统做了兼容,在linux下redis_fsync就是fsync,文件读写也有自己的缓冲区,一旦开启了自动同步io.file.autosync,则每写入一定数量io.file.buffered的数据,就进行同步fsync(fileno(fp))。
1 | /* Returns 1 or 0 for success/failure. */ |
接下来的两个io分别是connection io和 file descriptor io, 前者只实现了从socket中读取数据的接口,后者只实现了向fd中写数据的接口(This target is used to write the RDB file to pipe, when the master just streams the data to the replicas without creating an RDB on-disk image (diskless replication option))。
rdb.c rdb.h
rdbSaveRio
直接看函数rdbSaveRio的实现,第一部分是一些准备工作,RDB的版本被储存到了字符串magic中
1 | int rdbSaveRio(rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) { |
第二部分rdbWriteRaw直接把magic版本数据写入rdb输出流,rdbSaveInfoAuxFields写入了一些kv对,分别是redis-ver,redis-bits,ctime和used-mem。
对于rdbSaveModulesAux,他是module.c和module.h中的内容,大概就是保存了一个modules字典。
1 | int rdbSaveInfoAuxFields(rio *rdb, int rdbflags, rdbSaveInfo *rsi) { |
第三部分开始处理数据库,其主体如下。依次写入了数据库的编号、数据库kv个数,数据库超时kv个数。
1 | int rdbSaveRio(rio *rdb, int *error, int rdbflags, rdbSaveInfo *rsi) { |
第三部分的while循环中,对整个数据库的kv字典进行了迭代,依次写入了rio的流。
1 | /* Iterate this DB writing every entry */ |
最后一部分,写入了结束符和checksum
1 | /* If we are storing the replication information on disk, persist |
rdbSave
首先rdbSave创建了一个名为temp-pid.rdb的文件,该文件将用于输出rdb的结果。
1 | int rdbSave(char *filename, rdbSaveInfo *rsi) { |
然后使用该文件初始化rio流,并根据配置文件rio是否进行自动刷盘。
1 | int rdbSave(char *filename, rdbSaveInfo *rsi) { |
接着执行rdbSaveRio,并刷盘
1 | int rdbSave(char *filename, rdbSaveInfo *rsi) { |
最后把这个rdb文件命名为filename,并结束rdb。
rdbSaveBackground
fork出一个子进程,子进程执行rdb任务。
1 | int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) { |
Makefile
acl.c
ae.c
ae.h
ae_epoll.c
ae_evport.c
ae_kqueue.c
ae_select.c
anet.c
anet.h
aof.c
asciilogo.h
atomicvar.h
bio.c
bio.h
bitops.c
blocked.c
childinfo.c
cli_common.c
cli_common.h
cluster.c
cluster.h
config.c
config.h
connection.c
connection.h
connhelpers.h
crc16.c
crc16_slottable.h
crc64.c
crc64.h
crcspeed.c
crcspeed.h
db.c
debug.c
debugmacro.h
defrag.c
endianconv.c
endianconv.h
evict.c
expire.c
fmacros.h
geo.c
geo.h
geohash.c
geohash.h
geohash_helper.c
geohash_helper.h
help.h
hyperloglog.c
latency.c
latency.h
lazyfree.c
listpack.c
listpack.h
listpack_malloc.h
localtime.c
lolwut.c
lolwut.h
lolwut5.c
lolwut6.c
lzf.h
lzfP.h
lzf_c.c
lzf_d.c
memtest.c
mkreleasehdr.sh
module.c
modules
monotonic.c
monotonic.h
multi.c
networking.c
notify.c
object.c
pqsort.c
pqsort.h
pubsub.c
quicklist.c
quicklist.h
rand.c
rand.h
rax.c
rax.h
rax_malloc.h
redis-benchmark.c
redis-check-aof.c
redis-check-rdb.c
redis-cli.c
redis-trib.rb
redisassert.c
redisassert.h
redismodule.h
release.c
replication.c
scripting.c
sdsalloc.h
sentinel.c
server.c
server.h
setcpuaffinity.c
setproctitle.c
sha1.c
sha1.h
sha256.c
sha256.h
siphash.c
slowlog.c
slowlog.h
solarisfixes.h
sort.c
sparkline.c
sparkline.h
stream.h
syncio.c
t_hash.c
t_list.c
t_set.c
t_stream.c
t_string.c
t_zset.c
testhelp.h
timeout.c
tls.c
tracking.c
util.c
util.h
valgrind.sup
version.h
zipmap.c
zipmap.h
zmalloc.c
zmalloc.h


- 本文作者: fightinggg
- 本文链接: http://fightinggg.github.io/yilia/yilia/QVAQR0.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!