Kafka概述 定义 Kafka是一个分布式的基于发布/订阅模式的消息队列,应用于大数据实时处理领域
消息队列的优点 主要是解耦和削峰
解耦
可恢复,如果系统中一部分组件失效,加入队列的消息仍然可以在系统恢复后被处理
削峰
灵活,可动态维护消息队列的集群
异步
消息队列的两种模式 点对点 一对一,消费者主动拉取消息,收到后清除
发布/订阅模式 一对多,消费者消费后,消息不会清除,当然也不是永久保留,
分两种,一个是发布者主动推送,另一个是消费者主动拉取,Kafka就是消费者主动拉取,
推送
拉取
不好照顾多个消费者的接受速度
主动拉取,由消费者决定
消费者要每过一段时间就询问有没有新消息,长轮询
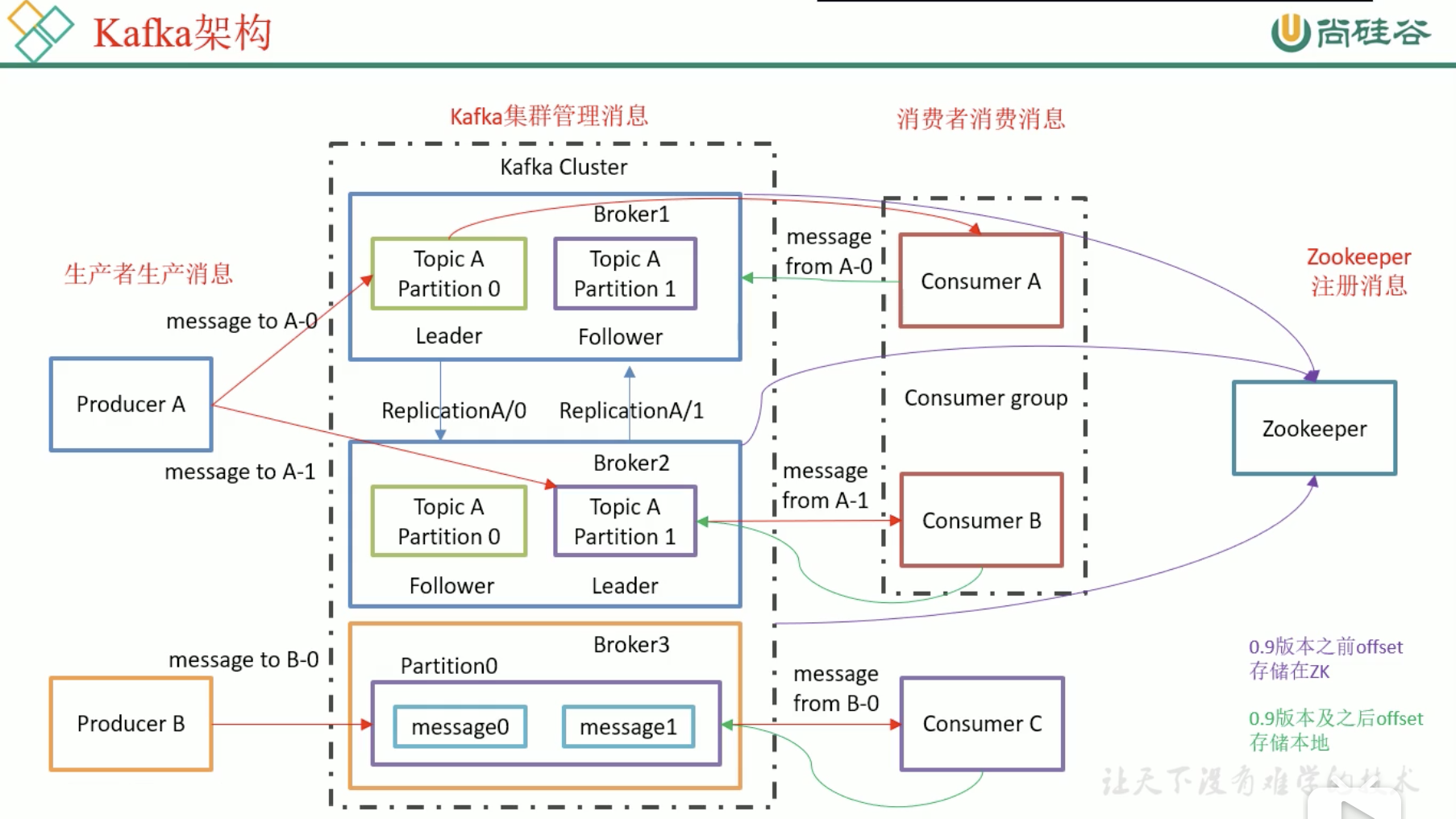
基础架构 Kafka Cluster 中有多个 Broker
Broker中有多个Topic Partion
每个Topic的多个Parttition,放在多个Broker上,可以提高Producer的并发,每个Topic Partition在其他Cluster上存有副本,用于备份,他们存在leader和follower,我们只找leader,不找follower
Topic是分区的,每个分区都是有副本的,分为leader和follower
消费者存在消费者组,一个分区只能被同一个组的某一个消费者消费,我们主要是把一个组当作一个大消费者,消费者组可以提高消费能力,消费者多了整个组的消费能力就高了,消费组中消费者的个数不要比消息多,不然就是浪费资源
Kafka利用Zookeeper来管理配置
0.9前消费者把自己消费的位置信息储存在Zookeeper中
0.9后是Kafka自己储存在某个主题中(减少了消费者和zk的连接)
我偷了个图
Kafka入门 常规安装 官网下载Kafka
brew install kafka
docker pull wurstmeister/kafka
Kafka安装 先安装zookeeper
然后安装kafka
1 2 3 4 5 docker run -d \ -eZK_HOSTS=zookeeper.zk \ --link zookeeper:zookeeper.zk \ --name=kafka \ kafkamanager/kafka-manager
Kafka compose 安装 1 2 3 4 5 mkdir ~/DockerDesktop mkdir ~/DockerDesktop/Kafka cd ~/DockerDesktop/Kafka mkdir node1 node2 node3 node4 node5 vim docker-compose.yml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 version: '3' services: Kafka1: image: wurstmeister/kafka hostname: Kafka1 environment: KAFKA_ADVERTISED_HOST_NAME: Kafka1 KAFKA_ADVERTISED_PORT: 9092 KAFKA_ZOOKEEPER_CONNECT: Zookeeper1:2181,Zookeeper2:2181,Zookeeper3:2181,Zookeeper4:2181,Zookeeper5:2181 volumes: - ~/DockerDesktop/Kafka/node1:/kafka external_links: - Zookeeper1 - Zookeeper2 - Zookeeper3 - Zookeeper4 - Zookeeper5 networks: default: ipv4_address: 172.17 .2 .1 Kafka2: image: wurstmeister/kafka hostname: Kafka2 environment: KAFKA_ADVERTISED_HOST_NAME: Kafka2 KAFKA_ADVERTISED_PORT: 9092 KAFKA_ZOOKEEPER_CONNECT: Zookeeper1:2181,Zookeeper2:2181,Zookeeper3:2181,Zookeeper4:2181,Zookeeper5:2181 volumes: - ~/DockerDesktop/Kafka/node2:/kafka external_links: - Zookeeper1 - Zookeeper2 - Zookeeper3 - Zookeeper4 - Zookeeper5 networks: default: ipv4_address: 172.17 .2 .2 Kafka3: image: wurstmeister/kafka hostname: Kafka3 environment: KAFKA_ADVERTISED_HOST_NAME: Kafka3 KAFKA_ADVERTISED_PORT: 9092 KAFKA_ZOOKEEPER_CONNECT: Zookeeper1:2181,Zookeeper2:2181,Zookeeper3:2181,Zookeeper4:2181,Zookeeper5:2181 volumes: - ~/DockerDesktop/Kafka/node3:/kafka external_links: - Zookeeper1 - Zookeeper2 - Zookeeper3 - Zookeeper4 - Zookeeper5 networks: default: ipv4_address: 172.17 .2 .3 Kafka4: image: wurstmeister/kafka hostname: Kafka4 environment: KAFKA_ADVERTISED_HOST_NAME: Kafka4 KAFKA_ADVERTISED_PORT: 9092 KAFKA_ZOOKEEPER_CONNECT: Zookeeper1:2181,Zookeeper2:2181,Zookeeper3:2181,Zookeeper4:2181,Zookeeper5:2181 volumes: - ~/DockerDesktop/Kafka/node4:/kafka external_links: - Zookeeper1 - Zookeeper2 - Zookeeper3 - Zookeeper4 - Zookeeper5 networks: default: ipv4_address: 172.17 .2 .4 Kafka5: image: wurstmeister/kafka hostname: Kafka5 environment: KAFKA_ADVERTISED_HOST_NAME: Kafka5 KAFKA_ADVERTISED_PORT: 9092 KAFKA_ZOOKEEPER_CONNECT: Zookeeper1:2181,Zookeeper2:2181,Zookeeper3:2181,Zookeeper4:2181,Zookeeper5:2181 volumes: - ~/DockerDesktop/Kafka/node5:/kafka external_links: - Zookeeper1 - Zookeeper2 - Zookeeper3 - Zookeeper4 - Zookeeper5 networks: default: ipv4_address: 172.17 .2 .5 networks: default: external: name: net17
执行下面的指令,Kafka集群开始运行
看到了输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 Kafka3_1 | [2020-04-18 10:26:27,441] INFO [Transaction Marker Channel Manager 1002]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager) Kafka4_1 | [2020-04-18 10:26:27,451] INFO [ExpirationReaper-1005-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper) Kafka5_1 | [2020-04-18 10:26:27,473] INFO [TransactionCoordinator id=1001] Starting up. (kafka.coordinator.transaction.TransactionCoordinator) Kafka5_1 | [2020-04-18 10:26:27,524] INFO [TransactionCoordinator id=1001] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator) Kafka5_1 | [2020-04-18 10:26:27,554] INFO [Transaction Marker Channel Manager 1001]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager) Kafka1_1 | [2020-04-18 10:26:27,635] INFO [TransactionCoordinator id=1003] Starting up. (kafka.coordinator.transaction.TransactionCoordinator) Kafka1_1 | [2020-04-18 10:26:27,644] INFO [TransactionCoordinator id=1003] Startup complete. (kafka.coordinator.transaction.TransactionCoordinator) Kafka1_1 | [2020-04-18 10:26:27,669] INFO [Transaction Marker Channel Manager 1003]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager) Kafka2_1 | [2020-04-18 10:26:27,748] INFO [ExpirationReaper-1004-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper) Kafka4_1 | [2020-04-18 10:26:27,753] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread) Kafka3_1 | [2020-04-18 10:26:27,843] INFO [ExpirationReaper-1002-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper) Kafka4_1 | [2020-04-18 10:26:27,882] INFO [SocketServer brokerId=1005] Started data-plane processors for 1 acceptors (kafka.network.SocketServer) Kafka4_1 | [2020-04-18 10:26:27,945] INFO Kafka version: 2.4.1 (org.apache.kafka.common.utils.AppInfoParser) Kafka4_1 | [2020-04-18 10:26:27,950] INFO Kafka commitId: c57222ae8cd7866b (org.apache.kafka.common.utils.AppInfoParser) Kafka4_1 | [2020-04-18 10:26:27,955] INFO Kafka startTimeMs: 1587205587891 (org.apache.kafka.common.utils.AppInfoParser) Kafka4_1 | [2020-04-18 10:26:27,976] INFO [KafkaServer id=1005] started (kafka.server.KafkaServer) Kafka2_1 | [2020-04-18 10:26:27,989] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread) Kafka1_1 | [2020-04-18 10:26:28,076] INFO [ExpirationReaper-1003-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper) Kafka3_1 | [2020-04-18 10:26:28,095] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread) Kafka2_1 | [2020-04-18 10:26:28,190] INFO [SocketServer brokerId=1004] Started data-plane processors for 1 acceptors (kafka.network.SocketServer) Kafka2_1 | [2020-04-18 10:26:28,239] INFO Kafka version: 2.4.1 (org.apache.kafka.common.utils.AppInfoParser) Kafka2_1 | [2020-04-18 10:26:28,241] INFO Kafka commitId: c57222ae8cd7866b (org.apache.kafka.common.utils.AppInfoParser) Kafka2_1 | [2020-04-18 10:26:28,243] INFO Kafka startTimeMs: 1587205588196 (org.apache.kafka.common.utils.AppInfoParser) Kafka2_1 | [2020-04-18 10:26:28,244] INFO [KafkaServer id=1004] started (kafka.server.KafkaServer) Kafka3_1 | [2020-04-18 10:26:28,253] INFO [SocketServer brokerId=1002] Started data-plane processors for 1 acceptors (kafka.network.SocketServer) Kafka3_1 | [2020-04-18 10:26:28,292] INFO Kafka version: 2.4.1 (org.apache.kafka.common.utils.AppInfoParser) Kafka3_1 | [2020-04-18 10:26:28,295] INFO Kafka commitId: c57222ae8cd7866b (org.apache.kafka.common.utils.AppInfoParser) Kafka3_1 | [2020-04-18 10:26:28,297] INFO Kafka startTimeMs: 1587205588257 (org.apache.kafka.common.utils.AppInfoParser) Kafka3_1 | [2020-04-18 10:26:28,313] INFO [KafkaServer id=1002] started (kafka.server.KafkaServer) Kafka1_1 | [2020-04-18 10:26:28,327] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread) Kafka5_1 | [2020-04-18 10:26:28,365] INFO [ExpirationReaper-1001-AlterAcls]: Starting (kafka.server.DelayedOperationPurgatory$ExpiredOperationReaper) Kafka1_1 | [2020-04-18 10:26:28,533] INFO [SocketServer brokerId=1003] Started data-plane processors for 1 acceptors (kafka.network.SocketServer) Kafka1_1 | [2020-04-18 10:26:28,582] INFO Kafka version: 2.4.1 (org.apache.kafka.common.utils.AppInfoParser) Kafka1_1 | [2020-04-18 10:26:28,582] INFO Kafka commitId: c57222ae8cd7866b (org.apache.kafka.common.utils.AppInfoParser) Kafka1_1 | [2020-04-18 10:26:28,584] INFO Kafka startTimeMs: 1587205588534 (org.apache.kafka.common.utils.AppInfoParser) Kafka1_1 | [2020-04-18 10:26:28,607] INFO [KafkaServer id=1003] started (kafka.server.KafkaServer) Kafka5_1 | [2020-04-18 10:26:28,931] INFO [/config/changes-event-process-thread]: Starting (kafka.common.ZkNodeChangeNotificationListener$ChangeEventProcessThread) Kafka5_1 | [2020-04-18 10:26:29,129] INFO [SocketServer brokerId=1001] Started data-plane processors for 1 acceptors (kafka.network.SocketServer) Kafka5_1 | [2020-04-18 10:26:29,218] INFO Kafka version: 2.4.1 (org.apache.kafka.common.utils.AppInfoParser) Kafka5_1 | [2020-04-18 10:26:29,218] INFO Kafka commitId: c57222ae8cd7866b (org.apache.kafka.common.utils.AppInfoParser) Kafka5_1 | [2020-04-18 10:26:29,220] INFO Kafka startTimeMs: 1587205589130 (org.apache.kafka.common.utils.AppInfoParser) Kafka5_1 | [2020-04-18 10:26:29,222] INFO [KafkaServer id=1001] started (kafka.server.KafkaServer)
同时我们在Zookeeper集群也看到了输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 Zookeeper1_1 | 2020-04-18 10:26:09,983 [myid:1] - WARN [QuorumPeer[myid=1](plain=0.0.0.0:2181)(secure=disabled):Follower@170] - Got zxid 0x500000001 expected 0x1 Zookeeper1_1 | 2020-04-18 10:26:09,990 [myid:1] - INFO [SyncThread:1:FileTxnLog@284] - Creating new log file: log.500000001 Zookeeper5_1 | 2020-04-18 10:26:09,988 [myid:5] - INFO [SyncThread:5:FileTxnLog@284] - Creating new log file: log.500000001 Zookeeper2_1 | 2020-04-18 10:26:10,002 [myid:2] - WARN [QuorumPeer[myid=2](plain=0.0.0.0:2181)(secure=disabled):Follower@170] - Got zxid 0x500000001 expected 0x1 Zookeeper2_1 | 2020-04-18 10:26:10,045 [myid:2] - INFO [SyncThread:2:FileTxnLog@284] - Creating new log file: log.500000001 Zookeeper4_1 | 2020-04-18 10:26:10,059 [myid:4] - WARN [QuorumPeer[myid=4](plain=0.0.0.0:2181)(secure=disabled):Follower@170] - Got zxid 0x500000001 expected 0x1 Zookeeper1_1 | 2020-04-18 10:26:10,087 [myid:1] - INFO [CommitProcessor:1:LearnerSessionTracker@116] - Committing global session 0x500000589e20000 Zookeeper5_1 | 2020-04-18 10:26:10,092 [myid:5] - INFO [CommitProcessor:5:LeaderSessionTracker@104] - Committing global session 0x500000589e20000 Zookeeper2_1 | 2020-04-18 10:26:10,093 [myid:2] - INFO [CommitProcessor:2:LearnerSessionTracker@116] - Committing global session 0x500000589e20000 Zookeeper3_1 | 2020-04-18 10:26:10,071 [myid:3] - WARN [QuorumPeer[myid=3](plain=0.0.0.0:2181)(secure=disabled):Follower@170] - Got zxid 0x500000001 expected 0x1 Zookeeper4_1 | 2020-04-18 10:26:10,098 [myid:4] - INFO [SyncThread:4:FileTxnLog@284] - Creating new log file: log.500000001 Zookeeper3_1 | 2020-04-18 10:26:10,109 [myid:3] - INFO [SyncThread:3:FileTxnLog@284] - Creating new log file: log.500000001 Zookeeper1_1 | 2020-04-18 10:26:10,113 [myid:1] - INFO [CommitProcessor:1:LearnerSessionTracker@116] - Committing global session 0x100000589b30000 Zookeeper2_1 | 2020-04-18 10:26:10,126 [myid:2] - INFO [CommitProcessor:2:LearnerSessionTracker@116] - Committing global session 0x100000589b30000 Zookeeper2_1 | 2020-04-18 10:26:10,141 [myid:2] - INFO [CommitProcessor:2:LearnerSessionTracker@116] - Committing global session 0x200000589b20000 Zookeeper4_1 | 2020-04-18 10:26:10,144 [myid:4] - INFO [CommitProcessor:4:LearnerSessionTracker@116] - Committing global session 0x500000589e20000 Zookeeper3_1 | 2020-04-18 10:26:10,137 [myid:3] - INFO [CommitProcessor:3:LearnerSessionTracker@116] - Committing global session 0x500000589e20000 Zookeeper1_1 | 2020-04-18 10:26:10,171 [myid:1] - INFO [CommitProcessor:1:LearnerSessionTracker@116] - Committing global session 0x200000589b20000 Zookeeper3_1 | 2020-04-18 10:26:10,199 [myid:3] - INFO [CommitProcessor:3:LearnerSessionTracker@116] - Committing global session 0x100000589b30000 Zookeeper4_1 | 2020-04-18 10:26:10,176 [myid:4] - INFO [CommitProcessor:4:LearnerSessionTracker@116] - Committing global session 0x100000589b30000 Zookeeper4_1 | 2020-04-18 10:26:10,202 [myid:4] - INFO [CommitProcessor:4:LearnerSessionTracker@116] - Committing global session 0x200000589b20000 Zookeeper3_1 | 2020-04-18 10:26:10,203 [myid:3] - INFO [CommitProcessor:3:LearnerSessionTracker@116] - Committing global session 0x200000589b20000 Zookeeper4_1 | 2020-04-18 10:26:10,204 [myid:4] - INFO [CommitProcessor:4:LearnerSessionTracker@116] - Committing global session 0x200000589b20001 Zookeeper4_1 | 2020-04-18 10:26:10,209 [myid:4] - INFO [CommitProcessor:4:LearnerSessionTracker@116] - Committing global session 0x200000589b20002 Zookeeper2_1 | 2020-04-18 10:26:10,224 [myid:2] - INFO [CommitProcessor:2:LearnerSessionTracker@116] - Committing global session 0x200000589b20001 Zookeeper3_1 | 2020-04-18 10:26:10,227 [myid:3] - INFO [CommitProcessor:3:LearnerSessionTracker@116] - Committing global session 0x200000589b20001 Zookeeper3_1 | 2020-04-18 10:26:10,241 [myid:3] - INFO [CommitProcessor:3:LearnerSessionTracker@116] - Committing global session 0x200000589b20002 Zookeeper2_1 | 2020-04-18 10:26:10,243 [myid:2] - INFO [CommitProcessor:2:LearnerSessionTracker@116] - Committing global session 0x200000589b20002 Zookeeper5_1 | 2020-04-18 10:26:10,245 [myid:5] - INFO [CommitProcessor:5:LeaderSessionTracker@104] - Committing global session 0x100000589b30000 Zookeeper5_1 | 2020-04-18 10:26:10,260 [myid:5] - INFO [CommitProcessor:5:LeaderSessionTracker@104] - Committing global session 0x200000589b20000 Zookeeper5_1 | 2020-04-18 10:26:10,270 [myid:5] - INFO [CommitProcessor:5:LeaderSessionTracker@104] - Committing global session 0x200000589b20001 Zookeeper5_1 | 2020-04-18 10:26:10,307 [myid:5] - INFO [CommitProcessor:5:LeaderSessionTracker@104] - Committing global session 0x200000589b20002 Zookeeper1_1 | 2020-04-18 10:26:10,403 [myid:1] - INFO [CommitProcessor:1:LearnerSessionTracker@116] - Committing global session 0x200000589b20001 Zookeeper1_1 | 2020-04-18 10:26:10,407 [myid:1] - INFO [CommitProcessor:1:LearnerSessionTracker@116] - Committing global session 0x200000589b20002
Kafka操作 开始操作
1 2 3 docker exec -it kafka_Kafka1_1 bash cd /opt/kafka/bin ls
我们可以看到一大堆东西
1 2 3 4 5 6 7 connect-distributed.sh kafka-console-producer.sh kafka-log-dirs.sh kafka-server-start.sh windows connect-mirror-maker.sh kafka-consumer-groups.sh kafka-mirror-maker.sh kafka-server-stop.sh zookeeper-security-migration.sh connect-standalone.sh kafka-consumer-perf-test.sh kafka-preferred-replica-election.sh kafka-streams-application-reset.sh zookeeper-server-start.sh kafka-acls.sh kafka-delegation-tokens.sh kafka-producer-perf-test.sh kafka-topics.sh zookeeper-server-stop.sh kafka-broker-api-versions.sh kafka-delete-records.sh kafka-reassign-partitions.sh kafka-verifiable-consumer.sh zookeeper-shell.sh kafka-configs.sh kafka-dump-log.sh kafka-replica-verification.sh kafka-verifiable-producer.sh kafka-console-consumer.sh kafka-leader-election.sh kafka-run-class.sh trogdor.sh
指定Zookeeper1,看看消息,结果啥都没有,因为kafka中没有消息
1 kafka-topics.sh --zookeeper Zookeeper1:2181 --list
创建主题, –topic 定义topic名字,–replication-factor定义副本数量,–partitions定义分区数量, 我们创建3个副本一个分区的主题first
1 kafka-topics.sh --zookeeper Zookeeper1:2181 --create --replication-factor 3 --partitions 1 --topic first
看到输出
然后使用kafka-topics.sh --zookeeper Zookeeper1:2181 --list就可以看到输出了一个first
现在我们回到docker外面的宿主机 的终端
1 2 cd ~/DockerDesktop/Kafkals node1/kafka-logs-Kafka1/ node2/kafka-logs-Kafka2 node3/kafka-logs-Kafka3 node4/kafka-logs-Kafka4 node5/kafka-logs-Kafka5
得到了输出,由此可见,我们的node3,node4,node5上分别保留了first的副本,这里还有一个细节,我们现在是在kafka1上执行的命令,这也能说明我们的集群是搭建成功了的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 node1/kafka-logs-Kafka1/: cleaner-offset-checkpoint log-start-offset-checkpoint meta.properties recovery-point-offset-checkpoint replication-offset-checkpoint node2/kafka-logs-Kafka2: cleaner-offset-checkpoint log-start-offset-checkpoint meta.properties recovery-point-offset-checkpoint replication-offset-checkpoint node3/kafka-logs-Kafka3: cleaner-offset-checkpoint first-0 log-start-offset-checkpoint meta.properties recovery-point-offset-checkpoint replication-offset-checkpoint node4/kafka-logs-Kafka4: cleaner-offset-checkpoint first-0 log-start-offset-checkpoint meta.properties recovery-point-offset-checkpoint replication-offset-checkpoint node5/kafka-logs-Kafka5: cleaner-offset-checkpoint first-0 log-start-offset-checkpoint meta.properties recovery-point-offset-checkpoint replication-offset-checkpoint
然后我们回到docker中,多来几次
1 2 3 4 kafka-topics.sh --zookeeper Zookeeper2:2181 --create --replication-factor 3 --partitions 1 --topic second kafka-topics.sh --zookeeper Zookeeper3:2181 --create --replication-factor 3 --partitions 1 --topic third kafka-topics.sh --zookeeper Zookeeper4:2181 --create --replication-factor 3 --partitions 1 --topic four kafka-topics.sh --zookeeper Zookeeper5:2181 --create --replication-factor 3 --partitions 1 --topic five
最后再查看宿主机 中的磁盘映射,这里一切正常,并且访问zookeeper集群中的任意一台机器都可行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 node1/kafka-logs-Kafka1/: cleaner-offset-checkpoint log-start-offset-checkpoint recovery-point-offset-checkpoint second-0 five-0 meta.properties replication-offset-checkpoint third-0 node2/kafka-logs-Kafka2: cleaner-offset-checkpoint log-start-offset-checkpoint recovery-point-offset-checkpoint second-0 four-0 meta.properties replication-offset-checkpoint node3/kafka-logs-Kafka3: cleaner-offset-checkpoint five-0 log-start-offset-checkpoint recovery-point-offset-checkpoint first-0 four-0 meta.properties replication-offset-checkpoint node4/kafka-logs-Kafka4: cleaner-offset-checkpoint five-0 meta.properties replication-offset-checkpoint third-0 first-0 log-start-offset-checkpoint recovery-point-offset-checkpoint second-0 node5/kafka-logs-Kafka5: cleaner-offset-checkpoint four-0 meta.properties replication-offset-checkpoint first-0 log-start-offset-checkpoint recovery-point-offset-checkpoint third-0
全删掉
1 2 3 4 5 kafka-topics.sh --delete --zookeeper Zookeeper1:2181 --topic first kafka-topics.sh --delete --zookeeper Zookeeper1:2181 --topic second kafka-topics.sh --delete --zookeeper Zookeeper1:2181 --topic third kafka-topics.sh --delete --zookeeper Zookeeper1:2181 --topic four kafka-topics.sh --delete --zookeeper Zookeeper1:2181 --topic five
看到输出,在我的集群中,我发先几秒钟后,就被删干净了
1 2 Topic first is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true .
为了后续的操作,我们重新创建一个新的主题
1 kafka-topics.sh --zookeeper Zookeeper5:2181 --create --replication-factor 3 --partitions 2 --topic first
随便起一台Kafka1, 作为生产者, 这里可以用localhost是因为他自己就是集群的一部分
1 kafka-console-producer.sh --topic first --broker-list localhost:9092
再起另外 一台Kafka2作为消费者,这台就开始等待了
1 kafka-console-consumer.sh --topic first --bootstrap-server localhost:9092
在生成者中输出>hello I am producer, 我们就能在消费者中看到,那么过时的消费者怎么办呢?我们使用上面的指令再起一台消费者Kafka3, 发现他并不能收到hello那条消息了,在生成者中输入>this is the second msg,发现kafka2和kafka3都可以收到消息,然后我们使用下面的指令再其一台Kafka4,等待片刻,发现kafka4收到了所有的消息
1 kafka-console-consumer.sh --topic first --bootstrap-server localhost:9092 --from-beginning
在宿主机中输入
1 ls node1/kafka-logs-Kafka1/ node2/kafka-logs-Kafka2 node3/kafka-logs-Kafka3 node4/kafka-logs-Kafka4 node5/kafka-logs-Kafka5
得到输出,可以看到offsets是轮流保存的, 因为分区是为了负载均衡,而备份是为了容错
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 node1/kafka-logs-Kafka1/: __consumer_offsets-14 __consumer_offsets-29 __consumer_offsets-4 __consumer_offsets-9 log-start-offset-checkpoint replication-offset-checkpoint __consumer_offsets-19 __consumer_offsets-34 __consumer_offsets-44 cleaner-offset-checkpoint meta.properties __consumer_offsets-24 __consumer_offsets-39 __consumer_offsets-49 first-1 recovery-point-offset-checkpoint node2/kafka-logs-Kafka2: __consumer_offsets-0 __consumer_offsets-20 __consumer_offsets-35 __consumer_offsets-5 log-start-offset-checkpoint replication-offset-checkpoint __consumer_offsets-10 __consumer_offsets-25 __consumer_offsets-40 cleaner-offset-checkpoint meta.properties __consumer_offsets-15 __consumer_offsets-30 __consumer_offsets-45 first-0 recovery-point-offset-checkpoint node3/kafka-logs-Kafka3: __consumer_offsets-13 __consumer_offsets-28 __consumer_offsets-38 __consumer_offsets-8 log-start-offset-checkpoint replication-offset-checkpoint __consumer_offsets-18 __consumer_offsets-3 __consumer_offsets-43 cleaner-offset-checkpoint meta.properties __consumer_offsets-23 __consumer_offsets-33 __consumer_offsets-48 first-0 recovery-point-offset-checkpoint node4/kafka-logs-Kafka4: __consumer_offsets-1 __consumer_offsets-21 __consumer_offsets-36 __consumer_offsets-6 first-1 recovery-point-offset-checkpoint __consumer_offsets-11 __consumer_offsets-26 __consumer_offsets-41 cleaner-offset-checkpoint log-start-offset-checkpoint replication-offset-checkpoint __consumer_offsets-16 __consumer_offsets-31 __consumer_offsets-46 first-0 meta.properties node5/kafka-logs-Kafka5: __consumer_offsets-12 __consumer_offsets-22 __consumer_offsets-37 __consumer_offsets-7 log-start-offset-checkpoint replication-offset-checkpoint __consumer_offsets-17 __consumer_offsets-27 __consumer_offsets-42 cleaner-offset-checkpoint meta.properties __consumer_offsets-2 __consumer_offsets-32 __consumer_offsets-47 first-1 recovery-point-offset-checkpoint
查看zk中的数据,起一台zk,执行zkCli.sh, 再执行ls /, 其中除了zookeeper文件以外,其他的数据都是Kafka的,部分终端显示如下
1 2 3 4 5 6 7 8 9 10 11 12 Welcome to ZooKeeper! 2020-04-19 07:03:58,554 [myid:localhost:2181] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1154] - Opening socket connection to server localhost/127.0.0.1:2181. 2020-04-19 07:03:58,557 [myid:localhost:2181] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1156] - SASL config status: Will not attempt to authenticate using SASL (unknown error) JLine support is enabled 2020-04-19 07:03:58,638 [myid:localhost:2181] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@986] - Socket connection established, initiating session, client: /127.0.0.1:41878, server: localhost/127.0.0.1:2181 2020-04-19 07:03:58,690 [myid:localhost:2181] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1420] - Session establishment complete on server localhost/127.0.0.1:2181, session id = 0x1000223de0e000b, negotiated timeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: localhost:2181(CONNECTED) 0] ls / [admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, log_dir_event_notification, zookeeper]
Kafka架构深入 文件储存 面向主题,消息按照主题分类,生产者生产消息,消费者消费消息
topic是逻辑概念, partition是物理概念,因为文件夹是用topic+parttiton命名的
1 2 bash-4.4 00000000000000000000.index 00000000000000000000.log 00000000000000000000.timeindex leader-epoch-checkpoint
Kafka的配置文件中有谈到, 即上面的000000.log最多只能保存1G,当他超过1G以后,会创建新的.log
1 2 log.segment.bytes =1073741824
分片和索引 1 2 3 4 5 6 00000000000000000000.index 00000000000000000000.log 00000000000000170410.index 00000000000000170410.log 00000000000000239430.index 00000000000000239430.log
文件名其实值得是当前片段(segment)中最小的消息的偏移量,log只存数据,index存消息在log中的偏移量
当我们要寻找某个消息的时候,先通过二分消息的编号,找到该消息再哪个index中,由于index中的数据都是等长的,所以可以直接用乘法定位index文件中的偏移量,然后根据这个偏移量定位到log文件中的位置
生产者 分区 方便扩展,提高并发,可以指定分区发送,可以指定key发送(key被hash成分区号), 可以不指定分区不指定key发送(会被随机数轮循)
数据可靠性保证 怎么保证可靠?Kafka需要给我们返回值,但是是leader写成功后返回还是follower成功后返回呢?哪个策略好呢?
副本数据同步策略
方案
优点
缺点
半数以上同步则ack
延迟低
选举新leader的时候,容忍n台节点故障,需要2n+1个副本
完全同步则ack
选举新leader的时候,容忍n台节点故障,需要n+1个副本
延迟高
Kafka选择了完全同步才发送ack,这有一个问题,如果同步的时候,有一台机器宕机了,那么永远都不会发送ack了
ISR in-sync replica set
leader 动态维护了一个动态的ISR,只要这个集合中的机器同步完成,就发送ack,选举ISR的时候,根据节点的同步速度和信息差异的条数来决定,在高版本中只保留了同步速度,为什么呢?延迟为什么比数据重要?
由于生产者是按照批次生产的,如果我们保留信息差异,当生产者发送大量信息的时候,直接就拉开了leader和follower的信息差异条数,同步快的follower首先拉小了自己和leader信息差异,这时候他被加入ISR,但最一段时间后他会被同步慢但是,最终信息差异小的follower赶出ISR,这就导致了ISR频繁发生变化,意味着ZK中的节点频繁变化,这个选择不可取
acks
ack级别
操作
数据问题
0
leader收到后就返回ack
broker故障可能丢失数据
1
leader写入磁盘后ack
在follower同步前的leader故障可能导致丢失数据
-1/all
等待ISR的follower写入磁盘后返回ack
在follower同步后,broker发送ack前,leader故障则导致数据重复
acks=-1也会丢失数据,在ISR中只有leader一个的时候发生
数据一致性问题 HW(High Watermark) 高水位, 集群中所有节点都能提供的最新消息
LEO(Log End Offset) 节点各自能提供的最新消息
为了保证数据的一致性,我们只提供HW的消费,就算消息丢了后,消费者也不知道,他看起来就是一致性的
leader故障 当重新选择leader后,为了保证多个副本之间的数据一致性,会通知follower将各自的log文件高于HW的地方截断,重新同步,这里只能保证数据一致性,不能保证数据不丢失或者不重复
精准一致性(Exactly Once) ACKS 为 -1 则不会丢失数据,即Least Once
ACKS 为 1 则生产者的每条数据只发送一次, 即At Most Once
他们一个丢数据一个重复数据
幂等性 开启幂等性,将Producer参数中的enable.idompotence设置为true,Producer会被分配一个PID(Producer ID), 发往同一个Partition的消息会附带序列号,而Broker会对PID,Partition,SeqNumber做缓存,当具有相同的主键消息提交的时候,Broker只会持久化一条,但是要注意PID重启会变化,不同的Partition也有不同的主键,所以幂等性无法保证跨分区会话的Exactly Once。
消费者 分区分配策略 一个consumer group中有多个consumer,一个topic中有多个partition,那么怎么分配呢?
RoundRobin策略 1 2 3 4 Topic1: x0,x1,x2 Topic2: y0,y1,y2 -> [x0,y2,y1,y0,x1,x2] -> [x0,y1,x1],[y2,y0,x2]
把所有主题中的所有partition放到一起,按照hash值排序,然后轮循分配给消费者
这样太混乱了,不太好
Range策略 1 2 3 Topic1: x0,x1,x2 Topic2: y0,y1,y2 -> [x0,x1,y0,y1],[x2,y2]
对于每个主题分开考虑,各自截取一段,分给消费者,
负载不均衡了
重新分配 当消费者的个数发生变化的时候,就会触发重新分配
offset维护 按照消费者组、主题、分区来维护offset,不能按照消费者维护,要是这样就不能让消费者组具有动态性质了
1 2 3 4 ls /brokers ls /brokers/ids ls /brokers/topics ls /consumers
消费者会默认生成一个消费者组的编号,其中有offset/mytopic/0
单机高效读写 顺序写磁盘 写磁盘的时候一直使用追加,官方数据表明同样的磁盘,顺序写可以达到600M/s但是随机写只有100K/s,
零拷贝技术 一般情况下,用户读取文件需要操作系统来协助,先读到内核空间,然后读到用户空间,然后写入内核空间,最后写入磁盘,零拷贝技术允许直接将这个拷贝工作交给操作系统完成
Zookeeper Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线、topic分区副本分配和leader选举等工作
Kafka事务 Producer事务 引入全局唯一的Transaction ID,替代PID,为了管理Transaction,Kafka引入了Transaction Producer和Transaction Coordinator交互获得Transaction ID。
Consumer事务 相对弱一些,用户可以自己修改offset或者跨segment的消费如果出错并且等满7天以后,segment被删除了,这些都导致问题
Kafka API 消息发送流程 Kafka的Producer发送消息是异步消息,两个线程main和sender,
发送消息的时候分三步,先经过拦截器,然后经过序列化器,最后经过分区器,最后才发出去
创建kafka项目 springinit 里面选择kafka
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 bootstrap.servers =172.17.1.1:9092 acks =all retries =3 batch.size =16384 linger.ms =1 buffer.memory =33554432 key.serializer =org.apache.kafka.serialization.StringSerializer value.serializer =org.apache.kafka.serialization.StringSerializer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package com.wsx.study.kafka.debug;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerRecord;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.util.Properties;public class Main { public static void main (String[] args) { try { Properties properties = new Properties (); FileInputStream in = new FileInputStream ("KafkaProducer.properties" ); properties.load(in); in.close(); KafkaProducer<String, String> stringStringKafkaProducer = new KafkaProducer <>(properties); for (int i = 0 ; i < 10 ; i++) { stringStringKafkaProducer.send(new ProducerRecord <>("first" , "javarecord" + i)); } stringStringKafkaProducer.close(); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } }
然后创建消费者
1 kafka-console-consumer.sh --topic first --bootstrap-server localhost:9092
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 bootstrap.servers =172.17.2.1:9092 # 日了狗了,这些mac似乎不行了 acks =all retries =3 batch.size =16384 linger.ms =1 buffer.memory =33554432 key.serializer =org.apache.kafka.common.serialization.StringSerializer value.serializer =org.apache.kafka.common.serialization.StringSerializer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package com.wsx.study.kafka.debug;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.ProducerRecord;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream;import java.util.Properties;public class Main { public void test () { try { Properties properties = new Properties (); InputStream in = getClass().getClassLoader().getResourceAsStream("KafkaProducer.properties" ); properties.load(in); assert in != null ; in.close(); KafkaProducer<String, String> stringStringKafkaProducer = new KafkaProducer <>(properties); for (int i = 0 ; i < 1 ; i++) { stringStringKafkaProducer.send(new ProducerRecord <>("first" , "javarecord" + i)); } stringStringKafkaProducer.close(); } catch (IOException e) { e.printStackTrace(); } } public static void main (String[] args) { new Main ().test(); } }
消费者 1 2 3 4 5 6 7 for (int i = 0 ; i < 1 ; i++) { stringStringKafkaProducer.send(new ProducerRecord <>("first" , "javarecord" + i), (recordMetadata, e) -> { if (e==null ){ System.out.println(recordMetadata.offset()+recordMetadata.offset()); } }); }
自己写分区器 配置文件配置一下就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class MyPartitioner implements Partitioner { @Override public int partition (String s, Object o, byte [] bytes, Object o1, byte [] bytes1, Cluster cluster) { return 0 ; } @Override public void close () { } @Override public void configure (Map<String, ?> map) { } }
生产者 同理,
1 2 3 4 consumer.subscribe(Arrays.asList("first" )); while (true ){ ConsumerRecords<String,Strings> consumerRecods = consumer.poll(long timeout); }
如何–beginning auto.offset.reset 当没有初始offset或者offset被删除了(数据过期)就会启动earliest,从最老的数据开始消费,这个东西不是0,他叫earlist,是最早不是开头
默认值是latest, 因为命令行的创建出来的是新的消费者组,所以启用了earliest
想要重新开始消费,要设earlist且换新的消费者组
offset加速 消费者只会在启动的时候拉取一次offset,如果没有自动提交offset,那么消费者就不会提交,这会导致数据不一致,如果这个时候消费者被强制终止,那么你下一次跑这个代码的时候,还是从之前的offset开始消费,除非你提交
enable.auto.commit 可以按时间提交
手动提交 同步: 当前线程会阻塞直到offset提交成功
异步: 加一个回调函数就可以
问题 自动提交速度快可能丢数据,比如我还没处理完,他就提交了,然后我挂了,数据就丢了
自定义offset 由于消息往往对消费者而言,可能存在本地的sql中,所以就可以和数据以前做成一个事务,
这可以解决问题,但是碰到了rebalace问题,即当一个消费者挂了以后消息资源要重新分配,借助ConsumerRebalanceListener,点这里 , 自己维护一个消费者组数据、自己写代码,(可怕)
自定义拦截器 configure 读取配置信息
onSend(ProducerRecord) 拦截
onAcknowledgement(RecordMetadata,Exception), 这个和上面的回调函数一样,拦截器也会收到这个东西,
close 拦截
例子 现在有个需求,消息发送前在消息上加上时间挫,消息发送后打印发送成功次数和失败次数
1 2 3 4 5 6 7 8 9 10 11 @Override public ProducerRecord<String, String> onSend (ProducerRecord<String, String> producerRecord) { String value = producerRecord.value(); return new ProducerRecord <String, String>(producerRecord.topic(), producerRecord.partition(), producerRecord.timestamp(), producerRecord.key(), System.currentTimeMillis()+"," +producerRecord.value(), producerRecord.headers()); }
计数拦截器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class CountInterceptor implements ProducerInterceptor <String, String>{ int success = 0 ; int error = 0 ; @Override public ProducerRecord<String, String> onSend (ProducerRecord<String, String> producerRecord) { return null ; } @Override public void onAcknowledgement (RecordMetadata recordMetadata, Exception e) { if (e==null ){ success++; }else { error++; } } @Override public void close () { System.out.println("success:" +success); System.out.println("error:" +error); } @Override public void configure (Map<String, ?> map) { } }
注意如果拦截器太多,考虑使用拦截器链
拦截器、序列化器、分区器都是卸载配置文件中的
Kafka监控 Kafka Eagle
1 2 if ["x$KAFKA_HEAP_OPTS " = "x" ] then export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128...."
然后分发这个文件,再上传kafka-eagle-bin-1.3.7.tar.gz到集群的/opt/software中,
配置文件 可以跟踪多个集群
kafka.eagle.zk.cluster.alisa = cluster1,cluster2
cluster1.zk.list=ip:port,ip:port,…
保存的位置
cluster1.kafka.eagle.offset.storage=kafka
监控图表
kafka.eagle.metrics.charts=true
启动
bin/ke.sh start
http://192.168.9.102:8048/ke
有很多信息都能看到,
Kafka面试题 Kafka 的ISR OSR AR ISR+OSR=AR
HW LEO 高水位,LEO
怎么体现消息的顺序 区内有序
分区器、序列化器、拦截器 生产者的整体结构,几个线程 消费者组中的消费者个数超过了topic就会有消费者收不到数据对吗 对的
提交的是offset还是offset+1 是offset+1
什么时候重复消费 先处理数据后提交
什么时候漏消费 先提交后处理数据
创建topic背后的逻辑 zk中创建新的topic节点,触发controller的监听,controller创建topic然后更新metadata cache
topic分区可以增加吗? 可以,不可以减少
kafka内部有topic吗 有个offset
kafka分区分配的概念 Rodrobin和range
日志目录结构 二分->index->log
kafka controller的作用 相当于老大,他是干活的,他和zk通信,还通知其他人
kafka什么时候选举 选controller,leader,ISR
失效副本是什么 这个问题很奇怪,大概是想说重新选举leader的时候,那个HW变化
为什么kafka高效率 顺序写+0拷贝
架构 压测 有一个***perf-test.sh
消息积压,消费者消费能力不够怎么办 增加topic分区、提高消费者组的消费者数量、提高消费者每次拉取的数量(默认500)
参考资料 Kafka教程
docker安装kafka