

Kafka概述
定义
Kafka是一个分布式的基于发布/订阅模式的消息队列,应用于大数据实时处理领域
消息队列的优点
主要是解耦和削峰
- 解耦
- 可恢复,如果系统中一部分组件失效,加入队列的消息仍然可以在系统恢复后被处理
- 削峰
- 灵活,可动态维护消息队列的集群
- 异步
消息队列的两种模式
点对点
一对一,消费者主动拉取消息,收到后清除
发布/订阅模式
一对多,消费者消费后,消息不会清除,当然也不是永久保留,
分两种,一个是发布者主动推送,另一个是消费者主动拉取,Kafka就是消费者主动拉取,
| 推送 | 拉取 |
|---|---|
| 不好照顾多个消费者的接受速度 | 主动拉取,由消费者决定 |
| 消费者要每过一段时间就询问有没有新消息,长轮询 |
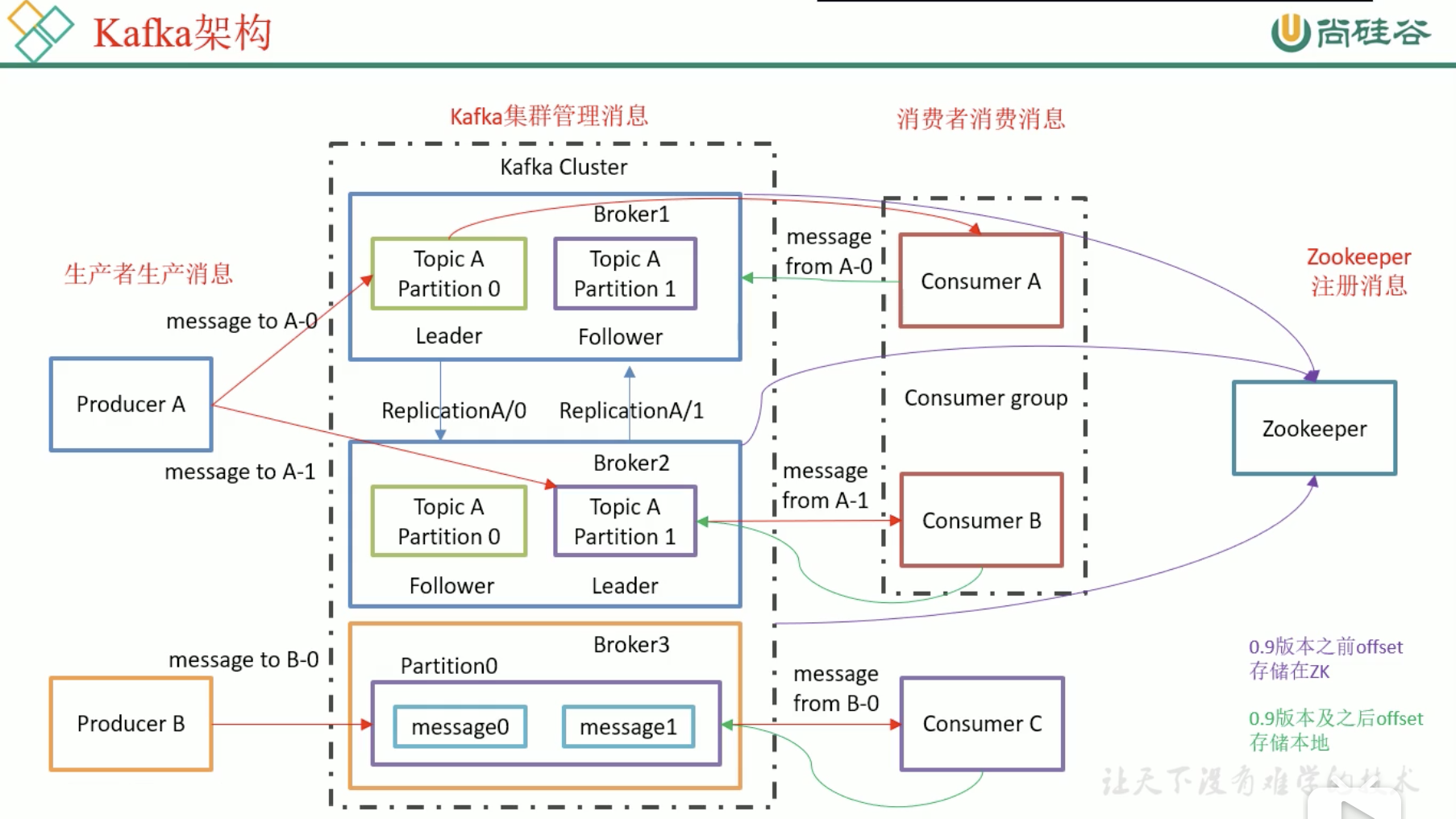
基础架构
Kafka Cluster 中有多个 Broker
Broker中有多个Topic Partion
每个Topic的多个Parttition,放在多个Broker上,可以提高Producer的并发,每个Topic Partition在其他Cluster上存有副本,用于备份,他们存在leader和follower,我们只找leader,不找follower
Topic是分区的,每个分区都是有副本的,分为leader和follower
消费者存在消费者组,一个分区只能被同一个组的某一个消费者消费,我们主要是把一个组当作一个大消费者,消费者组可以提高消费能力,消费者多了整个组的消费能力就高了,消费组中消费者的个数不要比消息多,不然就是浪费资源
Kafka利用Zookeeper来管理配置
0.9前消费者把自己消费的位置信息储存在Zookeeper中
0.9后是Kafka自己储存在某个主题中(减少了消费者和zk的连接)
Kafka入门
常规安装
官网下载Kafka
brew install kafka
docker pull wurstmeister/kafka
Kafka安装
先安装zookeeper
然后安装kafka
1 | docker run -d \ |
Kafka compose 安装
1 | mkdir ~/DockerDesktop |
1 | version: '3' |
执行下面的指令,Kafka集群开始运行
1 | docker-compose up |
看到了输出
1 | Kafka3_1 | [2020-04-18 10:26:27,441] INFO [Transaction Marker Channel Manager 1002]: Starting (kafka.coordinator.transaction.TransactionMarkerChannelManager) |
同时我们在Zookeeper集群也看到了输出
1 | Zookeeper1_1 | 2020-04-18 10:26:09,983 [myid:1] - WARN [QuorumPeer[myid=1](plain=0.0.0.0:2181)(secure=disabled):Follower@170] - Got zxid 0x500000001 expected 0x1 |
Kafka操作
开始操作
1 | docker exec -it kafka_Kafka1_1 bash |
我们可以看到一大堆东西
1 | connect-distributed.sh kafka-console-producer.sh kafka-log-dirs.sh kafka-server-start.sh windows |
指定Zookeeper1,看看消息,结果啥都没有,因为kafka中没有消息
1 | kafka-topics.sh --zookeeper Zookeeper1:2181 --list |
创建主题, –topic 定义topic名字,–replication-factor定义副本数量,–partitions定义分区数量, 我们创建3个副本一个分区的主题first
1 | kafka-topics.sh --zookeeper Zookeeper1:2181 --create --replication-factor 3 --partitions 1 --topic first |
看到输出
1 | Created topic first. |
然后使用kafka-topics.sh --zookeeper Zookeeper1:2181 --list就可以看到输出了一个first
1 | first |
现在我们回到docker外面的宿主机的终端
1 | cd ~/DockerDesktop/Kafka |
得到了输出,由此可见,我们的node3,node4,node5上分别保留了first的副本,这里还有一个细节,我们现在是在kafka1上执行的命令,这也能说明我们的集群是搭建成功了的
1 | node1/kafka-logs-Kafka1/: |
然后我们回到docker中,多来几次
1 | kafka-topics.sh --zookeeper Zookeeper2:2181 --create --replication-factor 3 --partitions 1 --topic second |
最后再查看宿主机中的磁盘映射,这里一切正常,并且访问zookeeper集群中的任意一台机器都可行
1 | node1/kafka-logs-Kafka1/: |
全删掉
1 | kafka-topics.sh --delete --zookeeper Zookeeper1:2181 --topic first |
看到输出,在我的集群中,我发先几秒钟后,就被删干净了
1 | Topic first is marked for deletion. |
为了后续的操作,我们重新创建一个新的主题
1 | kafka-topics.sh --zookeeper Zookeeper5:2181 --create --replication-factor 3 --partitions 2 --topic first |
随便起一台Kafka1, 作为生产者, 这里可以用localhost是因为他自己就是集群的一部分
1 | kafka-console-producer.sh --topic first --broker-list localhost:9092 |
再起另外一台Kafka2作为消费者,这台就开始等待了
1 | kafka-console-consumer.sh --topic first --bootstrap-server localhost:9092 |
在生成者中输出>hello I am producer, 我们就能在消费者中看到,那么过时的消费者怎么办呢?我们使用上面的指令再起一台消费者Kafka3, 发现他并不能收到hello那条消息了,在生成者中输入>this is the second msg,发现kafka2和kafka3都可以收到消息,然后我们使用下面的指令再其一台Kafka4,等待片刻,发现kafka4收到了所有的消息
1 | kafka-console-consumer.sh --topic first --bootstrap-server localhost:9092 --from-beginning |
在宿主机中输入
1 | ls node1/kafka-logs-Kafka1/ node2/kafka-logs-Kafka2 node3/kafka-logs-Kafka3 node4/kafka-logs-Kafka4 node5/kafka-logs-Kafka5 |
得到输出,可以看到offsets是轮流保存的, 因为分区是为了负载均衡,而备份是为了容错
1 | node1/kafka-logs-Kafka1/: |
查看zk中的数据,起一台zk,执行zkCli.sh, 再执行ls /, 其中除了zookeeper文件以外,其他的数据都是Kafka的,部分终端显示如下
1 | Welcome to ZooKeeper! |
Kafka架构深入
文件储存
面向主题,消息按照主题分类,生产者生产消息,消费者消费消息
topic是逻辑概念, partition是物理概念,因为文件夹是用topic+parttiton命名的
查看first-0的文件内容, 0000.log实际上存的是数据,不是日志
1 | bash-4.4# ls |
Kafka的配置文件中有谈到, 即上面的000000.log最多只能保存1G,当他超过1G以后,会创建新的.log
1 | # The maximum size of a log segment file. When this size is reached a new log segment will be created. |
分片和索引
1 | 00000000000000000000.index |
文件名其实值得是当前片段(segment)中最小的消息的偏移量,log只存数据,index存消息在log中的偏移量
当我们要寻找某个消息的时候,先通过二分消息的编号,找到该消息再哪个index中,由于index中的数据都是等长的,所以可以直接用乘法定位index文件中的偏移量,然后根据这个偏移量定位到log文件中的位置
生产者
分区
方便扩展,提高并发,可以指定分区发送,可以指定key发送(key被hash成分区号), 可以不指定分区不指定key发送(会被随机数轮循)
数据可靠性保证
怎么保证可靠?Kafka需要给我们返回值,但是是leader写成功后返回还是follower成功后返回呢?哪个策略好呢?
副本数据同步策略
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上同步则ack | 延迟低 | 选举新leader的时候,容忍n台节点故障,需要2n+1个副本 |
| 完全同步则ack | 选举新leader的时候,容忍n台节点故障,需要n+1个副本 | 延迟高 |
Kafka选择了完全同步才发送ack,这有一个问题,如果同步的时候,有一台机器宕机了,那么永远都不会发送ack了
ISR
in-sync replica set
leader 动态维护了一个动态的ISR,只要这个集合中的机器同步完成,就发送ack,选举ISR的时候,根据节点的同步速度和信息差异的条数来决定,在高版本中只保留了同步速度,为什么呢?延迟为什么比数据重要?
由于生产者是按照批次生产的,如果我们保留信息差异,当生产者发送大量信息的时候,直接就拉开了leader和follower的信息差异条数,同步快的follower首先拉小了自己和leader信息差异,这时候他被加入ISR,但最一段时间后他会被同步慢但是,最终信息差异小的follower赶出ISR,这就导致了ISR频繁发生变化,意味着ZK中的节点频繁变化,这个选择不可取
acks
| ack级别 | 操作 | 数据问题 |
|---|---|---|
| 0 | leader收到后就返回ack | broker故障可能丢失数据 |
| 1 | leader写入磁盘后ack | 在follower同步前的leader故障可能导致丢失数据 |
| -1/all | 等待ISR的follower写入磁盘后返回ack | 在follower同步后,broker发送ack前,leader故障则导致数据重复 |
acks=-1也会丢失数据,在ISR中只有leader一个的时候发生
数据一致性问题
HW(High Watermark) 高水位, 集群中所有节点都能提供的最新消息
LEO(Log End Offset) 节点各自能提供的最新消息
为了保证数据的一致性,我们只提供HW的消费,就算消息丢了后,消费者也不知道,他看起来就是一致性的
leader故障
当重新选择leader后,为了保证多个副本之间的数据一致性,会通知follower将各自的log文件高于HW的地方截断,重新同步,这里只能保证数据一致性,不能保证数据不丢失或者不重复
精准一致性(Exactly Once)
ACKS 为 -1 则不会丢失数据,即Least Once
ACKS 为 1 则生产者的每条数据只发送一次, 即At Most Once
他们一个丢数据一个重复数据
幂等性
开启幂等性,将Producer参数中的enable.idompotence设置为true,Producer会被分配一个PID(Producer ID), 发往同一个Partition的消息会附带序列号,而Broker会对PID,Partition,SeqNumber做缓存,当具有相同的主键消息提交的时候,Broker只会持久化一条,但是要注意PID重启会变化,不同的Partition也有不同的主键,所以幂等性无法保证跨分区会话的Exactly Once。
消费者
分区分配策略
一个consumer group中有多个consumer,一个topic中有多个partition,那么怎么分配呢?
RoundRobin策略
1 | Topic1: x0,x1,x2 |
把所有主题中的所有partition放到一起,按照hash值排序,然后轮循分配给消费者
这样太混乱了,不太好
Range策略
1 | Topic1: x0,x1,x2 |
对于每个主题分开考虑,各自截取一段,分给消费者,
负载不均衡了
重新分配
当消费者的个数发生变化的时候,就会触发重新分配
offset维护
按照消费者组、主题、分区来维护offset,不能按照消费者维护,要是这样就不能让消费者组具有动态性质了
进入zk中
1 | ls /brokers # 查看kafka集群 |
消费者会默认生成一个消费者组的编号,其中有offset/mytopic/0
单机高效读写
顺序写磁盘
写磁盘的时候一直使用追加,官方数据表明同样的磁盘,顺序写可以达到600M/s但是随机写只有100K/s,
零拷贝技术
一般情况下,用户读取文件需要操作系统来协助,先读到内核空间,然后读到用户空间,然后写入内核空间,最后写入磁盘,零拷贝技术允许直接将这个拷贝工作交给操作系统完成
Zookeeper
Kafka集群中有一个broker会被选举为Controller,负责管理集群broker的上下线、topic分区副本分配和leader选举等工作
Kafka事务
Producer事务
引入全局唯一的Transaction ID,替代PID,为了管理Transaction,Kafka引入了Transaction Producer和Transaction Coordinator交互获得Transaction ID。
Consumer事务
相对弱一些,用户可以自己修改offset或者跨segment的消费如果出错并且等满7天以后,segment被删除了,这些都导致问题
Kafka API
消息发送流程
Kafka的Producer发送消息是异步消息,两个线程main和sender,
发送消息的时候分三步,先经过拦截器,然后经过序列化器,最后经过分区器,最后才发出去
创建kafka项目
springinit 里面选择kafka
1 | # 指定kafka集群 |
1 | package com.wsx.study.kafka.debug; |
然后创建消费者
1 | kafka-console-consumer.sh --topic first --bootstrap-server localhost:9092 |
1 | # 指定kafka集群 |
1 | package com.wsx.study.kafka.debug; |
消费者
1 | for (int i = 0; i < 1; i++) { |
自己写分区器
配置文件配置一下就可以了
1 | class MyPartitioner implements Partitioner { |
生产者
同理,
1 | consumer.subscribe(Arrays.asList("first")); |
如何–beginning
auto.offset.reset 当没有初始offset或者offset被删除了(数据过期)就会启动earliest,从最老的数据开始消费,这个东西不是0,他叫earlist,是最早不是开头
默认值是latest, 因为命令行的创建出来的是新的消费者组,所以启用了earliest
想要重新开始消费,要设earlist且换新的消费者组
offset加速
消费者只会在启动的时候拉取一次offset,如果没有自动提交offset,那么消费者就不会提交,这会导致数据不一致,如果这个时候消费者被强制终止,那么你下一次跑这个代码的时候,还是从之前的offset开始消费,除非你提交
enable.auto.commit
可以按时间提交
手动提交
同步: 当前线程会阻塞直到offset提交成功
异步: 加一个回调函数就可以
问题
自动提交速度快可能丢数据,比如我还没处理完,他就提交了,然后我挂了,数据就丢了
自动提交速度慢可能重复数据,我处理完了,他还没提交,然后我挂了,下次又来消费一次数据
手动提交也有这些问题
自定义offset
由于消息往往对消费者而言,可能存在本地的sql中,所以就可以和数据以前做成一个事务,
这可以解决问题,但是碰到了rebalace问题,即当一个消费者挂了以后消息资源要重新分配,借助ConsumerRebalanceListener,点这里, 自己维护一个消费者组数据、自己写代码,(可怕)
自定义拦截器
configure 读取配置信息
onSend(ProducerRecord) 拦截
onAcknowledgement(RecordMetadata,Exception), 这个和上面的回调函数一样,拦截器也会收到这个东西,
close 拦截
例子
现在有个需求,消息发送前在消息上加上时间挫,消息发送后打印发送成功次数和失败次数
时间拦截器
1 |
|
计数拦截器
1 | class CountInterceptor implements ProducerInterceptor<String, String>{ |
注意如果拦截器太多,考虑使用拦截器链
拦截器、序列化器、分区器都是卸载配置文件中的
Kafka监控
Kafka Eagle
修改Kafka的kafka-server-start.sh, 对其进行修改,
1 | if ["x$KAFKA_HEAP_OPTS" = "x"] then |
然后分发这个文件,再上传kafka-eagle-bin-1.3.7.tar.gz到集群的/opt/software中,
配置文件
可以跟踪多个集群
kafka.eagle.zk.cluster.alisa = cluster1,cluster2
cluster1.zk.list=ip:port,ip:port,…
保存的位置
cluster1.kafka.eagle.offset.storage=kafka
监控图表
kafka.eagle.metrics.charts=true
启动
bin/ke.sh start
有很多信息都能看到,
Kafka面试题
Kafka 的ISR OSR AR
ISR+OSR=AR
HW LEO
高水位,LEO
怎么体现消息的顺序
区内有序
分区器、序列化器、拦截器
生产者的整体结构,几个线程
消费者组中的消费者个数超过了topic就会有消费者收不到数据对吗
对的
提交的是offset还是offset+1
是offset+1
什么时候重复消费
先处理数据后提交
什么时候漏消费
先提交后处理数据
创建topic背后的逻辑
zk中创建新的topic节点,触发controller的监听,controller创建topic然后更新metadata cache
topic分区可以增加吗?
可以,不可以减少
kafka内部有topic吗
有个offset
kafka分区分配的概念
Rodrobin和range
日志目录结构
二分->index->log
kafka controller的作用
相当于老大,他是干活的,他和zk通信,还通知其他人
kafka什么时候选举
选controller,leader,ISR
失效副本是什么
这个问题很奇怪,大概是想说重新选举leader的时候,那个HW变化
为什么kafka高效率
顺序写+0拷贝
架构
压测
有一个***perf-test.sh
消息积压,消费者消费能力不够怎么办
增加topic分区、提高消费者组的消费者数量、提高消费者每次拉取的数量(默认500)
参考资料


- 本文作者: fightinggg
- 本文链接: http://fightinggg.github.io/yilia/yilia/Q90SQR.html
- 版权声明: 本博客所有文章除特别声明外,均采用 MIT 许可协议。转载请注明出处!